




In this post, I will summarise all that I learned about running Lambda functions with Rust in the last six months, highlighting the good, the performance and the bad things that I experienced using Rust in production.
Optimise for Lambda execution
Before starting, let's make a quick point on how to speed up a Lambda function execution.
First, each runtime could have some extra configuration like, for example, Node.js with:
AWS_NODEJS_CONNECTION_REUSE_ENABLED: 1
The default Node.js HTTP/HTTPS agent creates a new TCP connection for every new request. To avoid the cost of establishing a new connection, you can reuse an existing connection.
For Java, you can use the JAVA_TOOL_OPTIONS. Using this environment variable, you can change various aspects of the JVM configuration, including garbage collection functionality, memory settings, and the configuration for tiered compilation. For example, to change the tiered compilation level to 1, you would set the value of:
JAVA_TOOL_OPTIONS: -XX:+TieredCompilation -XX:TieredStopAtLevel=1
I want to recap the basics:
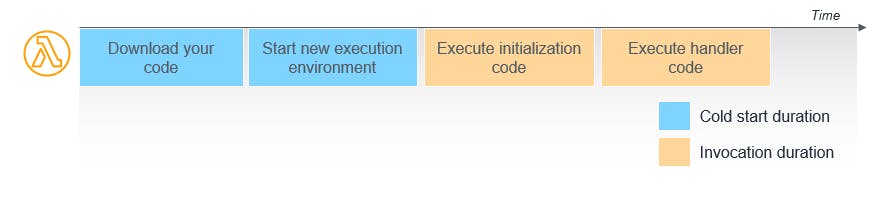
As the AWS article said:
When the Lambda service receives a request to run a function via the Lambda API, the service first prepares an execution environment. During this step, the service downloads the code for the function. Next, it creates an environment with the specified memory, runtime, and configuration. Once complete, Lambda runs any initialisation code outside of the event handler before finally running the handler code. The Lambda service retains the execution environment instead of destroying it immediately after execution.
As a developer, I am requested to optimise only:
- Bootstrap the runtime
- Code run
- Use arm64 architecture
This means I need to make sure:
- My package is small as possible
- Initialise my classes, SDK clients and database connections outside of the function handler
- Cache static assets locally in the /tmp directory.
Doing all of this will saves execution time and cost for subsequent invocations (Warm start).
On top of these basic rules, maybe it is good to mention:
- Avoiding fat lambda function
- Executing code in parallel when possible
Parallelism: Parallelism means that an application splits its tasks into smaller subtasks that can be processed in parallel, for example, on multiple CPUs simultaneously.
let mut tasks = Vec::with_capacity(event.records.len());
....
for record in event.records.into_iter() {
tasks.push(tokio::spawn(async move {
.....
do_something(&shared_client, &request)
.await
.map_or_else(|e| log::error!("Error {:?}", e), |_| ());
}))
}
join_all(tasks).await;
....
}
Concurrency: Concurrency means that an application is making progress on more than one task at the same time (concurrently).
// convert array in streams to use async
let mut records = stream::iter(event.records);
// processing one element at a time
while let Some(record) = records.next().await {
Rust
My journey with Rust started on Jan 6th 2022, and since then, I have written a bit about configuring it and showing some code comparisons. The posts are all under the series Serverless Rust.
I tried to showcase that Rust can be used outside of heavy network use cases or for the operating system or games but for a much higher-level purpose. In fact, after using .NET and mostly Node.js for AWS Lambda, I decided to push the boundaries of speed using a different runtime.
AWS Lambda runtime can be written in any programming language. A runtime is a program that runs a Lambda function's handler method when the function is invoked. It is possible to include a runtime in the function's deployment package in the form of an executable file named bootstrap. In this case, a crate maintained by AWS makes it very simple to tell Lambda service how to run applications written in Rust.
lambda_runtime = "0.5.1"
There are many examples of Lambda written in Rust, but I would like to stop for a moment on the basic dependencies needed to start a project:
[dependencies]
aws-config = "0.12.0" // AWS SDK config and credential provider implementations.
lambda_runtime = "0.5.1" // Lambda runtime
serde = {version = "1.0", features = ["derive"] } // framework for serializing and deserializing
serde_json = "1.0.68" // framework for serializing and deserializing
tokio = "1.13.0" // A runtime for writing asynchronous required for the lambda_runtime
tracing-subscriber = "0.3" // required to enable CloudWatch error logging by the runtime
As with pretty much all the runtimes, the template follows the same rules:
- Install your dependencies
- Import them
- Declare your handler
The result would be like:
// imports my libraries
use lambda_runtime::{service_fn, Error, LambdaEvent};
use serde_json::Value;
// expected by lambda_runtime to make the main function asynchronous
#[tokio::main]
// Result<(), Error> is the idiomatic way to handle errors in Rust instead of try catch them
// https://doc.rust-lang.org/rust-by-example/error/result.html#using-result-in-main
async fn main() -> Result<(), Error> {
// required to enable CloudWatch error logging by the runtime
tracing_subscriber::fmt()
// this needs to be set to false, otherwise ANSI color codes will
// show up in a confusing manner in CloudWatch logs.
.with_ansi(false)
// disabling time is handy because CloudWatch will add the ingestion time.
.without_time()
.init();
// some custom code to init all my classes, SDK etc outside of the handler
let app_client = MyAppClient::builder()
.init_something(xxx)
.init_something_else()
.build();
// this is necessary because rust is not supported as a provided runtime
lambda_runtime::run(service_fn(|event: LambdaEvent<Value>| {
execute(&app_client, event)
}))
.await?; //block until the results come back. The ? is to handle the propagation of the error.
Ok(()) // tell the caller that things were successful
}
// our handler maybe in the future will be the only thing that we will write
// app_client is my custom code that contains all the initialisation outside of the handler
// _event is the payload and it is going to be deserialised into Value
pub async fn execute(app_client: &dyn MyAppInitialisation, _event: LambdaEvent<Value>) -> Result<(), Error> {
//do something
Ok(())
}
There is no need to be afraid of Rust, and it is not much complex as other languages. It took me more or less a week to write my first Lambda that connected to DynamoDB and to be honest, and it was the same amount of time I wrote it for the first time in Node.js, .NET or Golang.
My original background is/was .NET and Java, so maybe it was much easier to get around ownership. Essentially, it is the idea that two pieces of code cannot simultaneously access the same part of memory.
It is a unique feature that allows Rust to make a memory safety guarantee without a garbage collector. Regardless of the programming language, the memory life cycle is pretty much always the same:
- Allocate the memory you need
- Use the allocated memory
- Release the allocated memory when it is not needed anymore
Languages like Javascript are all implicit. I declare my variable and the language runtime takes care of the rest via a garbage collector. I don't need to worry about what goes on the stack and what goes on the heap in garbage-collected languages. Data on the stack gets dropped once it goes out of scope. Data that lives on the heap is taken care of by the garbage collector once it's no longer needed.
To make it short, it is all good and makes a developer's life much easier.
Rust does not have garbage collection, and so as a developer, I can do one of three things:
- Move the data itself and give up ownership in the process
- Create a copy of the data and pass that along
- Pass a reference to the data and retain ownership, letting the recipient borrow it for a while.
It could be a lot to digest, but it is not a big thing. I got used and yes:
- Make the code more verbose
- Make things more complicated with parallelism
Because I want to be a good serverless programmer, I keep my Lambda code as small as possible without creating much complexity. Still, I am confident that the Rust community would be happy to talk and share some advice when the intricate problem arrives. I like to use:
Rust unit tests
Nowadays, I think everybody writes unit tests, and all the languages have an official library or the one to refer to. However, Rust comes with very basic support, which I saw only > 10 years ago when unit tests were not a thing, and so when I was researching, I just found something not very helpful:
fn prints_and_returns_10(a: i32) -> i32 {
println!("I got the value {}", a);
10
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn this_test_will_pass() {
let value = prints_and_returns_10(4);
assert_eq!(10, value);
}
#[test]
fn this_test_will_fail() {
let value = prints_and_returns_10(8);
assert_eq!(5, value);
}
}
While writing tests, I often need to setup something before tests run and perhaps something when the test finishes. All of this does not exist unless you go and find some library that usually is not perfect or actively maintained etc. Another thing that I struggled with was mocking. Because I am using AWS SDK libraries like DynamoDB, SQS, etc., I need to mock all to test my logic in total isolation.
Fortunately for me, there is an excellent crate Mockall maintained by angels and with the owner Alan Somers pretty active in helping the community when a question arises.
As you can read from the guide:
There are two ways to use Mockall. The easiest is to use #[automock]. It can mock most traits or structures with only a single impl block. For things it can't handle, there is mock!.
Whichever method is used, the basic idea is the same.
- Create a mock struct. Its name will be the same as the original, with "Mock" prepended.
- In your test, instantiate the mock struct with its new or default method.
- Set expectations on the mock struct. Each expectation can have required argument matches, a count of calls needed, and a required position in a Sequence. Each expectation must also have a return value.
- Supply the mock object to the code that you're testing. It will return the preprogrammed return values supplied in the previous step. Any access contrary to your expectations will cause a panic.
Example
I recently got interested in serverless multi-region configuration, and it turned out there are many AWS services that will help you to achieve a multi-region like:
Once I have time, I will publish a complete example project but for now, let's consider the CloudFront invalidation case of the Serverless cache scenario.
use aws_lambda_events::event::sqs::SqsEvent;
use aws_sdk_cloudfront::model::{invalidation_batch, paths};
use lambda_runtime::{service_fn, Error, LambdaEvent};
utils::injections::invalidation_di::{InvalidationAppClient, InvalidationAppInitialisation}};
use my_app::{dtos::invalidation_request::InvalidationRequest, utils::injections::invalidation_di::{InvalidationAppClient, InvalidationAppInitialisation}};
#[tokio::main]
async fn main() -> Result<(), Error> {
tracing_subscriber::fmt()
.with_ansi(false)
.without_time()
.init();
let config = aws_config::load_from_env().await;
let cloudfront_client = aws_sdk_cloudfront::Client::new(&config);
let distribution_name = std::env::var("DISTRIBUTION_NAME").expect("DISTRIBUTION_NAME must be set");
let app_client = InvalidationAppClient::builder()
.cloudfront_client(cloudfront_client)
.distribution_id(distribution_name)
.build();
lambda_runtime::run(service_fn(|event: LambdaEvent<SqsEvent>| {
execute(&app_client, event)
}))
.await?;
Ok(())
}
pub async fn execute(app_client: &dyn InvalidationAppInitialisation, event: LambdaEvent<SqsEvent>) -> Result<(), Error> {
println!("{:?}", event);
let mut items: Vec<String> = vec![];
for record in event.payload.records.into_iter() {
if let Some(body) = &record.body {
let request = serde_json::from_str::<InvalidationRequest>(&body)?;
items.push(format!("/?key1={}&key2={}", request.my_key1, request.my_key2));
}
}
let paths = paths::Builder::default()
.quantity(items.len().try_into().unwrap())
.set_items(Some(items))
.build();
let invalidation_batch = invalidation_batch::Builder::default()
.paths(paths)
.set_caller_reference(Some(format!("{}", app_client.get_timestamp())))
.build();
app_client.get_cloudfront_client()
.create_invalidation()
.distribution_id(app_client.get_distribution_id())
.invalidation_batch(invalidation_batch)
.send()
.await?;
Ok(())
}
#[cfg(test)]
mod tests {
use super::*;
use aws_sdk_cloudfront::{Client, Config, Credentials, Region};
use aws_smithy_client::{test_connection::TestConnection, erase::DynConnector};
use aws_smithy_http::body::SdkBody;
use lambda_http::Context;
use mockall::mock;
use my_app::error::ApplicationError;
async fn get_mock_config() -> aws_sdk_cloudfront::Config {
let cfg = aws_config::from_env()
.region(Region::new("eu-central-1"))
.credentials_provider(Credentials::new(
"accesskey",
"privatekey",
None,
None,
"dummy",
))
.load()
.await;
Config::new(&cfg)
}
fn get_request_builder() -> http::request::Builder {
http::Request::builder()
.header("content-type", "application/xml")
.uri(http::uri::Uri::from_static(
"https://cloudfront.amazonaws.com/2020-05-31/distribution/some_distribution/invalidation",
))
}
#[tokio::test]
async fn invalidate_key() -> Result<(), ApplicationError> {
// ARRANGE
let conn = TestConnection::new(vec![(
get_request_builder()
.body(SdkBody::from(
r#"<InvalidationBatch xmlns="http://cloudfront.amazonaws.com/doc/2020-05-31/"><Paths><Quantity>1</Quantity><Items><Path>/?key1=something&key2=something</Path></Items></Paths><CallerReference>1336468263</CallerReference></InvalidationBatch>"#,
))
.unwrap(),
http::Response::builder()
.status(200)
.body(SdkBody::from(r#"
<Invalidation>
<CreateTime>2019-12-05T18:40:49.413Z</CreateTime>
<Id>I2J0I21PCUYOIK</Id>
<InvalidationBatch>
<CallerReference>1336468263</CallerReference>
<Paths>
<Items>
<Path>/?key1=something&key2=something</Path>
</Items>
<Quantity>1</Quantity>
</Paths>
</InvalidationBatch>
<Status>InProgress</Status>
</Invalidation>
"#))
.unwrap(),
)]);
let client = Client::from_conf_conn(get_mock_config().await, DynConnector::new(conn.clone()));
let data = r#"{
"Records": [
{
"messageId": "059f34b4-87a3-46ab-83d2-661975830a7d",
"receiptHandle": "AQEBwJnKyrHDfsdgvbUMZj6rYigCgxlaS3SLy0a",
"body": "{\"key1\":\"something\",\"key2\":\"something\"}",
"attributes": {
"ApproximateReceiveCount": "1",
"SentTimestamp": "1545082649183",
"SenderId": "AIDAIENHSNOLO23YVJ4VO",
"ApproximateFirstReceiveTimestamp": "1545082649185"
},
"eventSource": "aws:sqs",
"eventSourceARN": "arn:aws:sqs:us-east-2:123456789012:my-queue",
"aws_region": "us-east-2"
}
]
}"#;
let sqs = serde_json::from_str::<SqsEvent>(&data).unwrap();
let context = Context::default();
let event = LambdaEvent::new(sqs, context);
mock! {
pub InvalidationAppClient {}
impl InvalidationAppInitialisation for InvalidationAppClient {
fn get_timestamp(&self) -> i64 {
1336468263
}
fn get_cloudfront_client(&self) -> aws_sdk_cloudfront::Client {
client
}
fn get_distribution_id(&self) -> String {
"something".clone()
}
}
}
let mut mock = MockInvalidationAppClient::new();
mock.expect_get_timestamp().times(1).return_const(1336468263);
mock.expect_get_cloudfront_client().times(1).returning(move || client.clone());
mock.expect_get_distribution_id().times(1).return_const("some_distribution");
// ACT
execute(&mock, event).await?;
// ASSERT
assert_eq!(conn.requests().len(), 1);
conn.assert_requests_match(&vec![]);
Ok(())
}
}
This code is straightforward:
- The Lambda is triggered by an SQS Event
- Sequentially, we handle the SQS Batch to collect all keys to invalidate in CloudFront
- We invalidate a batch of keys for a specific distribution
There is a lot in the unit tests part, and I will try to highlight each piece.
There is no "BeforeEach" or "OneTimeSetUp", so you need to write code to simulate. I will most likely write something to emulate the plumbing of my tests and write some generic implementation for mocking AWS SDK.
Mocking AWS SDK
In the test, two methods are called in the ARRANGE part of the unit test:
async fn get_mock_config() -> aws_sdk_cloudfront::Config {}
fn get_request_builder() -> http::request::Builder {}
They are methods to "mock" AWS SDK service, and to do such operation, I can use the TestConnection provided in each service, which allows me to simulate the request and response.
Be aware that if you have multiple services in your logic, you need to instantiate the TestConnection for each service, build a specific request for each service, and figure out what "content-type" to use and which "URI" to use.
Mocking Lambda event
With Rust, we have two crates for Lambda, and they could require different payloads.
With lambda_runtime:
lambda_runtime::run(service_fn(|event: LambdaEvent<SqsEvent>| {
execute(&app_client, event)
})).await?;
}
pub async fn execute(app_client: &dyn InvalidationAppInitialisation, event: LambdaEvent<SqsEvent>) -> Result<(), Error> { }
.....
#[tokio::test]
async fn my_test() -> Result<(), ApplicationError> {
let data = r#"{
"Records": [
{
"messageId": "059f34b4-87a3-46ab-83d2-661975830a7d",
"receiptHandle": "AQEBwJnKyrHDfsdgvbUMZj6rYigCgxlaS3SLy0a",
"body": "{\"key1\":\"something\",\"key2\":\"something\"}",
"attributes": {
"ApproximateReceiveCount": "1",
"SentTimestamp": "1545082649183",
"SenderId": "AIDAIENHSNOLO23YVJ4VO",
"ApproximateFirstReceiveTimestamp": "1545082649185"
},
"eventSource": "aws:sqs",
"eventSourceARN": "arn:aws:sqs:us-east-2:123456789012:my-queue",
"aws_region": "us-east-2"
}
]
}"#;
let sqs = serde_json::from_str::<SqsEvent>(&data).unwrap();
let context = Context::default();
let event = LambdaEvent::new(sqs, context);
...
}
if it was behind API Gateway REST and HTTP API lambda integrations with lambda_http:
lambda_http::run(service_fn(|event: Request| execute(&app_client, event))).await?;
...
pub async fn execute(app_client: &dyn InvalidationAppInitialisation, event: Request) > Result<impl IntoResponse, Error> { }
.....
#[tokio::test]
async fn my_test() -> Result<(), ApplicationError> {
let mut item = HashMap::new();
item.insert("xxxx".into(), vec!["key1".into()]);
let request = Request::default().with_query_string_parameters(item.clone());
//or in case of a post
let request = http::Request::builder()
.header("Content-Type", "application/json")
.body(Body::from(
r#"{"key1":"something", "key2": "something"}"#,
))
.unwrap();
...
}
Mocking a trait
To achieve maximum speed, I initialised my classes, SDK clients and database connections etc. outside of the function handler with some custom code, and I passed this to the handler method together with the Lambda payload:
let app_client = ListAppClient::builder()
.list_by_brand_query(query)
.dynamo_db_client(dynamodb_client.clone())
.build();
lambda_runtime::run(service_fn(|event: LambdaEvent<SqsEvent>| {
execute(&app_client, event)
})).await?;
MockAll can mock traits, in this case, InvalidationAppInitialisation.
pub async fn execute(app_client: &dyn InvalidationAppInitialisation, event: LambdaEvent<SqsEvent>) -> Result<(), Error> {
Inside the unit test in the ARRANGE part, there is MockAll syntax:
mock! {
pub InvalidationAppClient {}
impl InvalidationAppInitialisation for InvalidationAppClient {
fn get_timestamp(&self) -> i64 {
1336468263
}
fn get_cloudfront_client(&self) -> aws_sdk_cloudfront::Client {
client
}
fn get_distribution_id(&self) -> String {
"something".clone()
}
}
}
let mut mock = MockInvalidationAppClient::new();
mock.expect_get_timestamp().times(1).return_const(1336468263);
mock.expect_get_cloudfront_client().times(1).returning(move || client.clone());
mock.expect_get_distribution_id().times(1).return_const("some_distribution");
I need to override the methods that I want to mock and return the essential information to let the test pass without creating a real connection or worrying about implementing my class dependencies.
Mocking when borrower checker bites you back
At the start of this post, I mentioned using parallelism when it is possible.
If I want to handle all the SQS in parallel, I will write something like:
pub async fn execute(app_client: &dyn InvalidationAppInitialisation, event: LambdaEvent<SqsEvent>) -> Result<(), Error> {
let mut tasks = Vec::with_capacity(event.records.len());
....
for record in event.records.into_iter() {
// This will be the concrete init and it will not be possible to mock do_something()
// let shared_app_client = app_client.clone();
let shared_app_client = app_client.clone_to_arc();
tasks.push(tokio::spawn(async move {
if let Some(body) = &record.body {
let request = serde_json::from_str::<MyStruct>(&body);
if let Ok(request) = request {
shared_app_client.do_something(&request).await
.map_or_else(|e| {
println!("ERROR {:?}", e);
}, |_| ());
}
}
}));
}
join_all(tasks).await;
....
}
I am using The Atomic Reference Counter (Arc) to share immutable data across threads in a thread-safe way. In this case, we want to share the shared_app_client that holds the reference of my classes, SDK clients, database connections, etc.
To make possible the mocking, I need to implement a wrapper for my trait:
fn clone_to_arc(&self) -> Arc<dyn InvalidationAppInitialisation> {
Arc::new(self.clone())
}
With this in place, I can do this:
mock! {
pub InvalidationAppClient {}
impl InvalidationAppInitialisation for InvalidationAppClient {
....
fn clone_to_arc(&self) -> Arc<dyn InvalidationAppInitialisation> {
Arc::new(self.clone())
}
}
}
let mut mock = MockInvalidationAppClient::new();
mock.expect_clone_to_arc().times(1).returning(move || {
let mut m = MockInvalidationAppClient::new();
m.expect_do_something().times(1).returning(|_| Ok(()));
Arc::new(m)
});
Performance
Everybody knows that Rust and Golang are the fastest, followed by .NET and Java (only warm state) and, in the end, by Python and Node.js.
I am running AWS Lambda function loading stuff from S3 or DynamoDB, and I have achieved the following results:
| count | p50 | p90 | p99 | max | |
| warm | > 20M | 1.19ms | 1.29ms | 1.74ms | 108.42ms |
| cold | < 400 | 312.12ms | 416.21ms | 534.23ms | 1.11s |
| warm | > 12M | 13.78ms | 19.39ms | 36.49ms | 148.42ms |
| cold | < 200 | 102.56ms | 125.18 | 145.54ms | 157.13ms |
In my experience, the latency is all on the AWS network, so numbers can always be different, but I think they are pretty good.
If interested in performance comparison AWS published one application with multiple languages: