

Serverless Challenge - Is scaling achievable without the utilisation of a cache-aside pattern?


This article is titled Serverless Challenge as it explores the various ways and challenges of achieving scalability, cost-effectiveness, and maintainability in application development. These goals are often difficult to achieve simultaneously.
The application being discussed is cluster-based, and it is quite large. It uses Amazon ElastiCache for Redis in a cache-aside pattern.

A cache-aside flow can be summarised as follows:
Check the cache first to determine whether the data is available.
If the data is available, it is a cache hit, and the cached data is returned.
If the data isn’t available, it is a cache miss. The database is queried for the data. The cache is then populated with the data retrieved from the database, which is returned.
Please read more Source
The application works, but it has become enormous over the years, and the over-provision culture, "be ready just in case", is not fitting anymore.
Finally, the core values of serverless computing, which include paying only for what is used and letting providers handle infrastructure and scalability, are now being recognised at the management level.
Requirements
We want architecture that supports over 10,000 requests per second with ideally 100 ms response time
Keep the cost under control
Keep performances and integration with other services
The question here is:
Can Serverless fit these requirements?
The answer is yes but it is very complicated because, out of the box, Serverless services are not all the same, and they are not scaling all at the same level.
Out of the box, a Serverless application works only:
If your workload is low
If spiky traffic is inside the quotas
If you are not in the above case like me, you are entering minefields made of multiple great advice:
Convert all to Async
Request quotas increase
Do not use Serverless, for later on to hear, go back to Serverless
Through the years, I learned a few tricks have a look at this series, and I am convinced that pretty much all can be rewritten in a Serverless way with some compromise to keep in consideration.
To make it simpler, I assume two types of requests for my application:
GET
POST
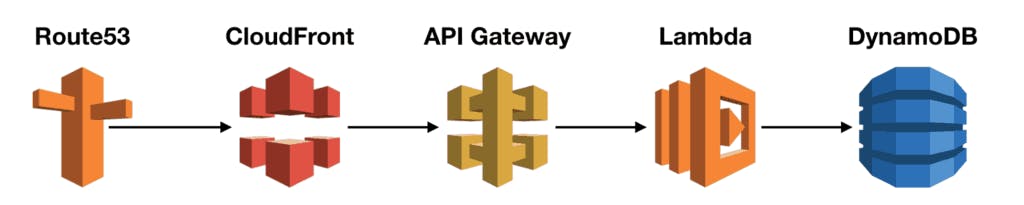
I want to discuss the synchronisation of GET requests and propose an architecture that simplifies the process. This architecture involves having only one endpoint, such as an API Gateway and a Lambda function. However, I would like to point out that the scalability of this approach is limited by the burst quota and downstream services used by the Lambda function.
Imagine I need to retrieve content for each request, which may consist of multiple items with an average size exceeding 100KB. There are various services available for storing data, but personally, I opted for S3 to keep a JSON file of that size.
Running a simple test, I have noticed the AWS SDK throwing errors:
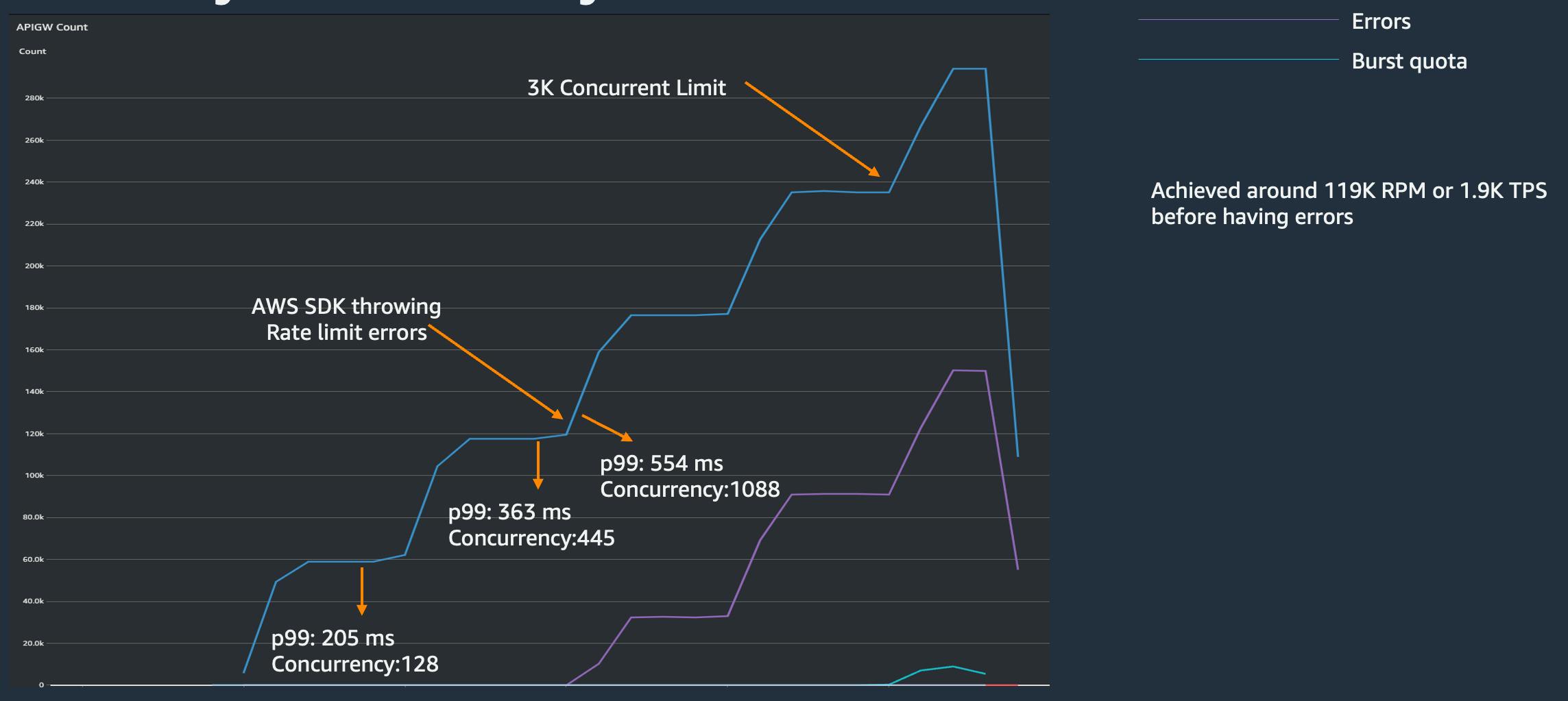
In my case, it was the S3 SLOW DOWN error, but similar can apply to other services like DynamoDB table being throttled.
A good practice to protect downstream services is to start caching and work with some degree of stale data.
I invite you to read an old but still actual article from AWS Serverless Hero Yan Cui.
I placed CloudFront in front of the API Gateway and set a cache expiration time of 3 minutes, which is suitable for my use case to maintain data freshness.
My flow can be summarised as follows:
Check in DynamoDB the files to load based on the GET parameters.
Load N files in parallel and do some transformation based on logic given by the parameters.
Return data to the client.
The flow is simple, and now, thanks to CloudFront, I can achieve the 10,000 RPS required, but the performances are not great:
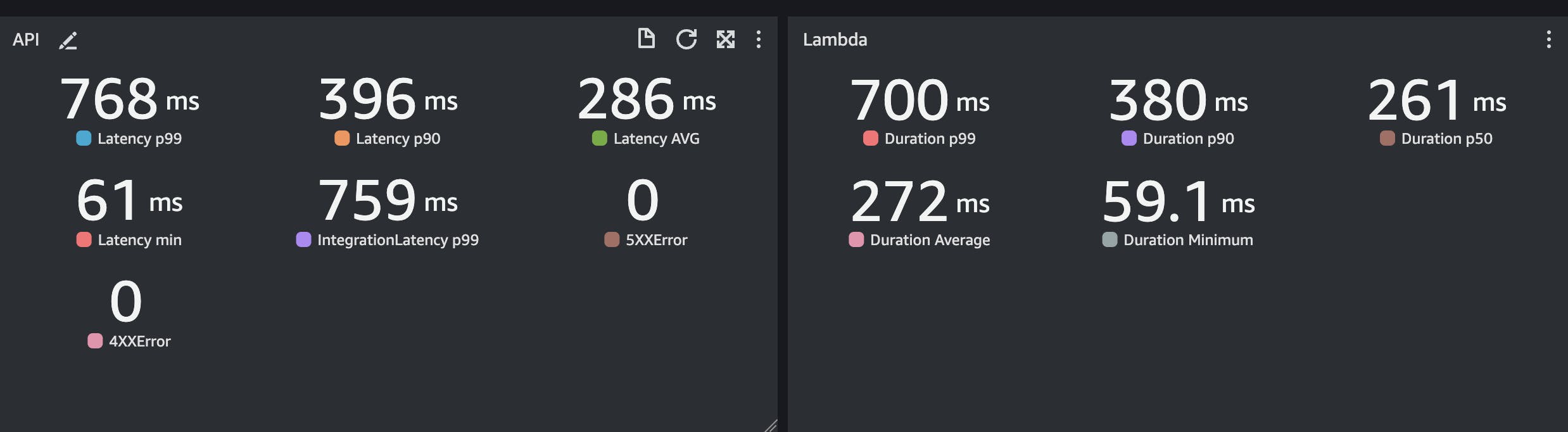
Moreover, there is the risk of a surge of requests after the 3 minutes of the CDN cache that could hit the S3 limitations.
Each S3 bucket can support a request rate of up to 3,500 PUT/COPY/POST/DELETE and 5,500 GET/HEAD requests per second. If you exceed these limits, you'll receive the SlowDown error.
I'm sure there's a way to work around it, but it will increase complexity and may not be worth the effort.
Conclusion
To address the issue, my next article will explore the cache-aside pattern in Lambda. This approach should lead to immediate performance gain. I have found that caching data can greatly improve performance. Still, I have hesitated to use clusters due to the complexity of choosing between Amazon API Gateway Cache, ElastiCache, or DAX. The multitude of options, including instance type, number of replicas, zones, and VPCs, can be overwhelming and time-consuming to configure.