




It all started because I was giving my Like to movies on Netflix, and someone asked me why. So I put my IT hat on and started explaining how services like Netflix have some complex logic that tracks the history of my interactions and cross-reference similar tastes with other members considering information like titles, actors, genres, etc.
From this, I got curious and took the opportunity to learn a new service Amazon Neptune. A graph database is one of the NoSQL databases, and they are a good fit when data must be connected and when the connection is more important than the schema structure.
Amazon Neptune
Amazon Neptune is a fully-managed graph database service and supports the popular graph query languages Apache TinkerPop Gremlin and W3C's SPARQL.
Neptune's main components are:
Primary DB instance – Supports read and write operations and performs all data modifications to the cluster volume.
Neptune replica – Connects to the same storage volume as the primary DB instance and supports only read operations (up to 15 Neptune Replicas).
Cluster volume – Neptune data is stored in the cluster volume. A cluster volume consists of copies of the data across multiple Availability Zones in a single AWS Region.
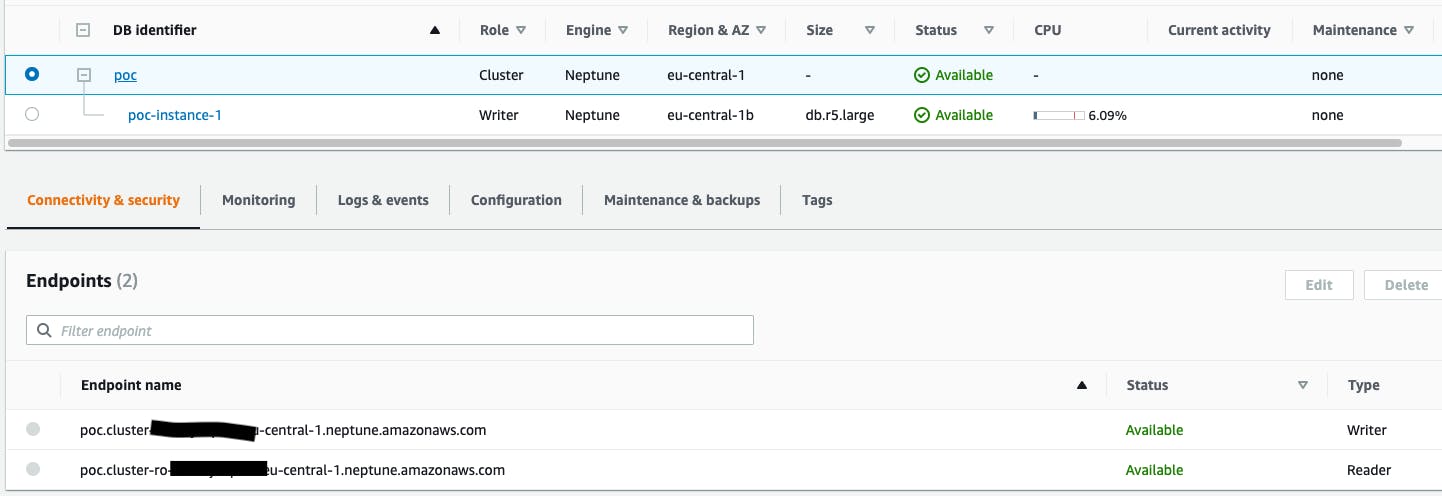
The cluster endpoint and reader endpoint provide support for high-availability scenarios, and this is because Neptune uses the endpoint mechanism to reroute connections when some DB instances are unavailable. For example, if the primary DB instance of a DB cluster fails, Neptune automatically fails over to a new primary DB instance. It either promotes an existing replica to a new primary DB instance or creates a new primary DB instance.
It is not serverless, so you pay for the instances by the hours and storage consumed. Refer to Amazon Neptune pricing.
I configured Neptune in a private subnet with a security group that allows access only for port 8182 and the security group where my Lambda functions are configured.
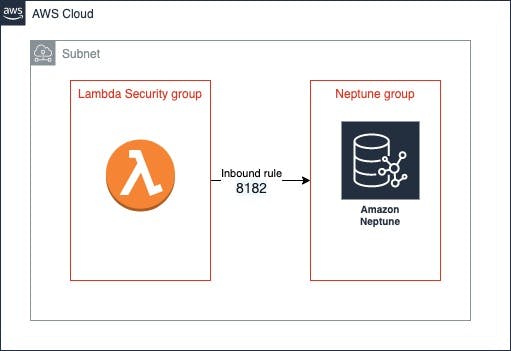
In your AWS account, you can configure a Lambda function to connect to private subnets in a virtual private cloud (VPC).
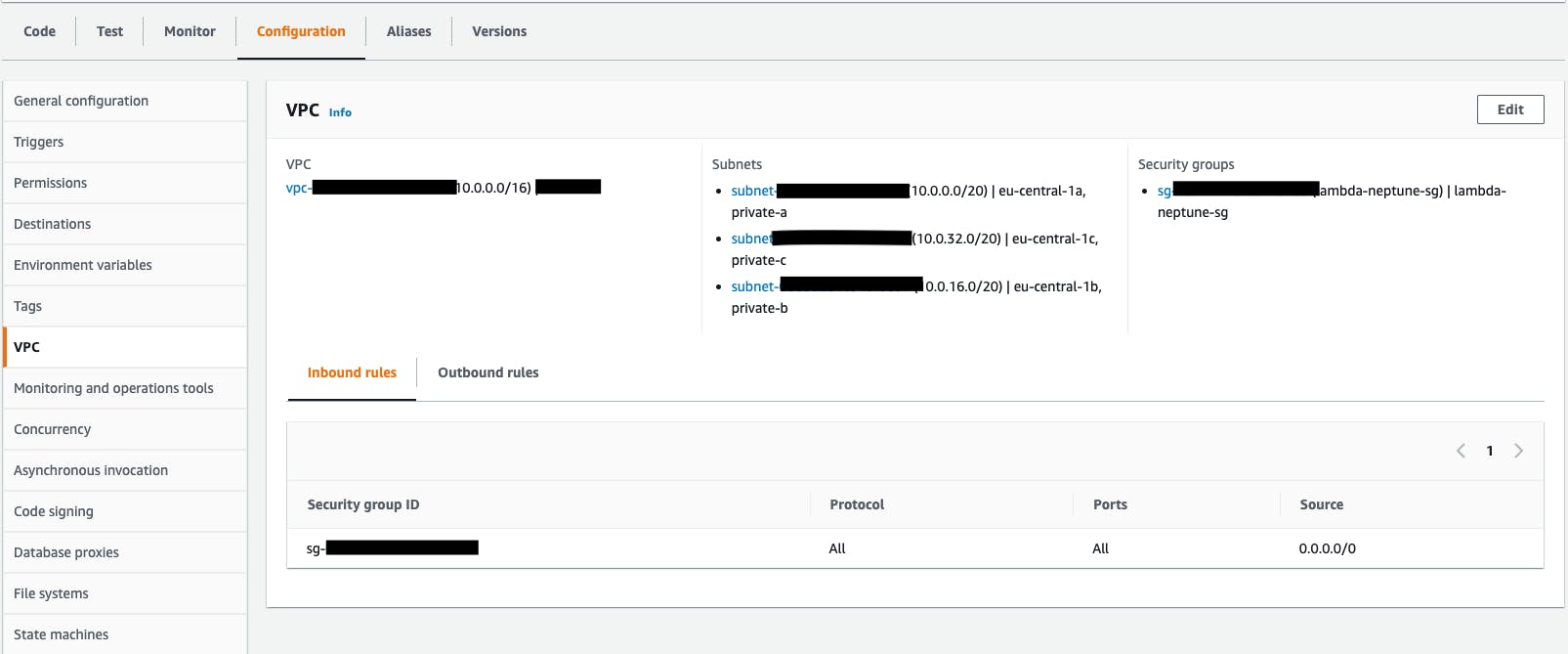
Running a Lamba into a VPC is not easy, especially if you have a particular type of load. Typical errors are:
- EC2ThrottledException - when the VPC does not have sufficient ENIs or subnet IPs.
- Client.NetworkInterfaceLimitExceeded - each lambda requires an ENI (Elastic Network Interface), and each region has a limit.
- Client.RequestLimitExceeded - The lambda functions hit the request rate limit of creating network interfaces (ENIs).
The quota can be increased, but it could be better. An option to avoid these problems could be some data export as a cache layer in front of Neptune, like in DynamoDB.
Amazon Neptune does not have a built-in user interface. I was expecting something similar to Neo4j
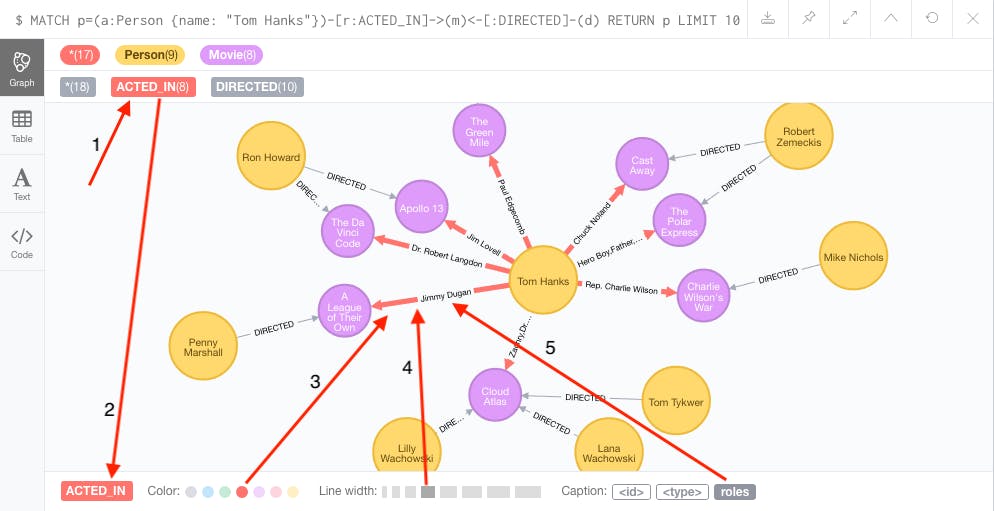
Instead, on top of your Neptune cost, Amazon asks you to use a Jupyter notebook using the Neptune workbench. Of course, I get billed for workbench resources through Amazon SageMaker, separately from your Neptune billing. Once it is all up and running, I can visualize my graph.
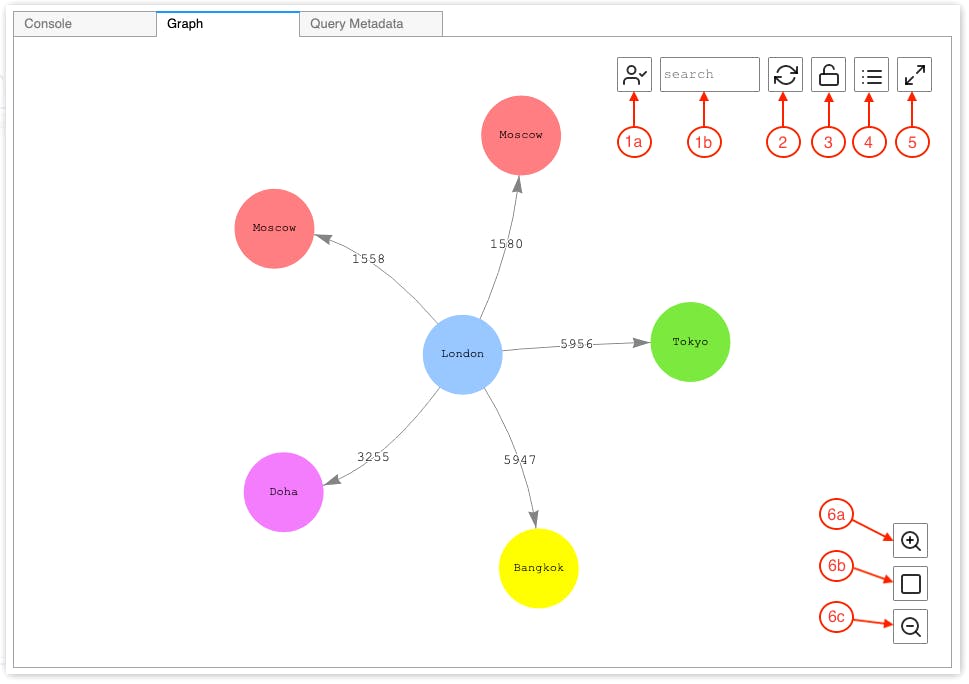
This should come for free or at least already available in the cluster deployment without paying extra.
The Amazon Neptune graph data is represented as a four-position (quad) element:
- subject (S)
- predicate (P)
- object (O)
- graph (G)
Each quad is a statement that asserts one or more resources, describing the type of relationship or property being defined. Refer to Neptune Graph Data Model.
From Relational to Graph
I have never worked with a graph database, so let me clarify the terminology.
A graph database has the following:
- Node/Vertex: represents an item in the graph.
- Edge/Relation: a connection between two nodes.
- Label: to indicate the type of vertex or edge.
- Property: key-value pairs.
If you want to see them side by side, it could be like this:
| Relational database | Graph |
| Table | Label |
| Row | Node/Vertex |
| Columns | Property |
| Relationships | Edge/Relation |
Loading data
To load data, I could create vertex and edges on-demand like this:
// VERTEX
await g.addV("actor")
.property("firstname", "Tom")
.property("lastname", "Hanks")
.next();
// EDGE
await g.V("tom_hanks_id").as('source')
.V("forrest_gump_id").as('destination')
.addE("actor_in")
.from_('source').to('destination')
.next();
Instead, to load a lot of data in one go, there is Neptune Bulk Loader.
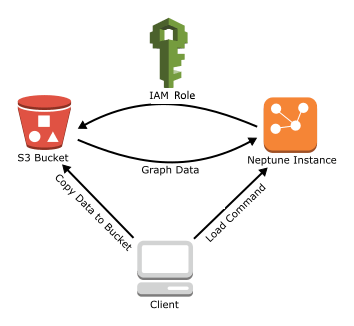
Copy the data files to an Amazon Simple Storage Service (Amazon S3) bucket.
Create an IAM role with Read and List access to the bucket.
Create an Amazon S3 VPC endpoint.
Start the Neptune loader by sending a request via HTTP to the Neptune DB instance.
The Neptune DB instance assumes the IAM to load the bucket's data.
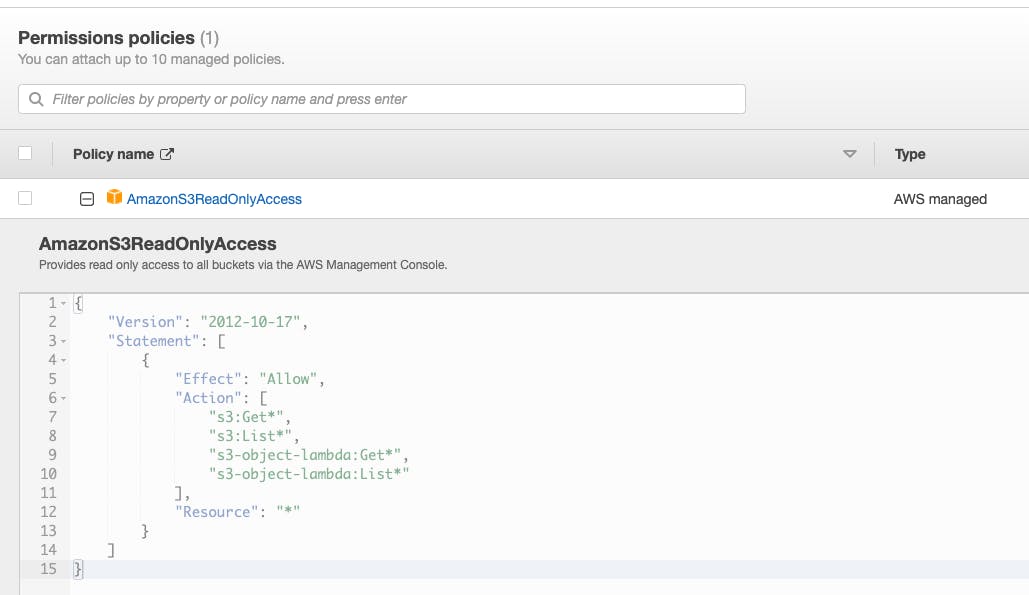
I created a role using the AWS Managed policy from the console, but I suggest restricting the resource access to the specific bucket.
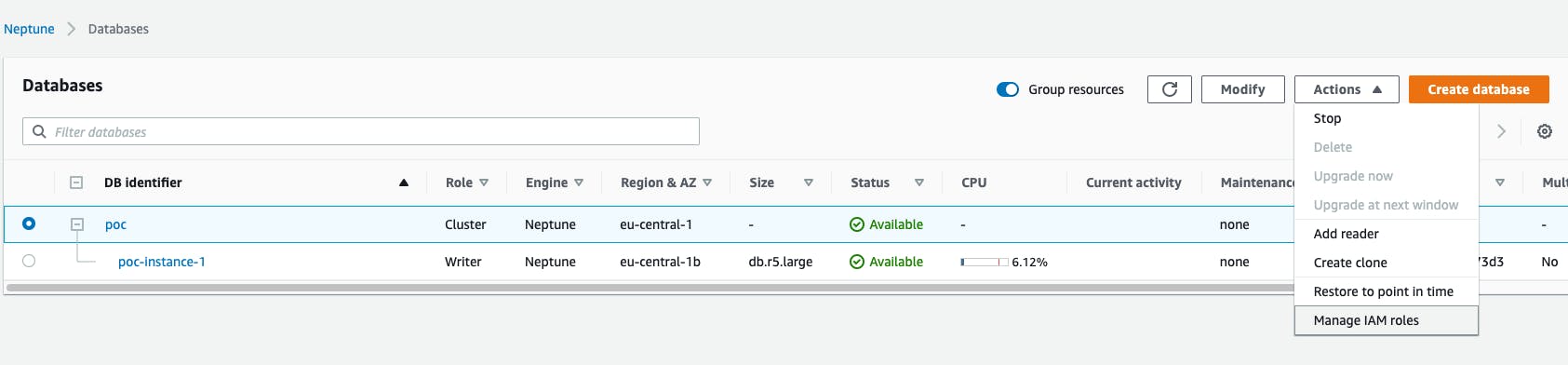
And I added the role to the Neptune instance from the console.
To prepare the data, you have two ways I think:
- Build your script, for example, csv processing
- ETL Process for Transforming and Loading Data Into Amazon Neptune
Either way, you need to follow the specific formats for the Neptune loader API:
- CSV format (csv) for property graph / Gremlin
- CSV format (csv) for property graph / openCypher
- N-Triples (ntriples) format for RDF / SPARQL
- N-Quads (nquads) format for RDF / SPARQL
- RDF/XML (rdfxml) format for RDF / SPARQL
- Turtle (turtle) format for RDF / SPARQL
Once the data is in the S3 bucket, I need to call the Bulk Load API and to do so, I created an EC2 in the same security group of Neptune and accessed it using AWS Systems Manager Session Manager. So I have added an IAM Role to my ec2 machine:
And with the instance running, I can select it and click connect:

Once inside, I run this command:
curl -X POST \
-H 'Content-Type: application/json' \
https://your-neptune-endpoint:8182/loader -d '
{
"source" : "s3://bucket-name/object-key-name",
"format" : "csv",
"iamRoleArn" : "arn:aws:iam::account-id:role/role-name",
"region" : "region",
"failOnError" : "FALSE",
"parallelism" : "MEDIUM",
"updateSingleCardinalityProperties" : "FALSE",
"queueRequest" : "TRUE"
}'
This will start the process, and keep in mind that files of almost 1 GB could take hours (I think it depends on the size of the machine).
The previous command will return a response like:
{
"status" : "200 OK",
"payload" : {
"loadId" : "635798ae-b306-4d56-a1d3-165dc3d56007"
}
}
And you can use the loadId to see the progress:
curl -G' https://your-neptune-endpoint:8182/loader/635798ae-b306-4d56-a1d3-165dc3d56007'
Availability
Neptune volume spans multiple Availability Zones in a single AWS Region, and each Availability Zone contains a copy of the cluster volume data. In the presence of reading replicas, if a failure happens, the services should automatically handle the restoration of the service in less than 2 minutes. If there are no read replicas, the primary instance is recreated, and it could take up to 10 minutes to recover. Neptune automatically backs up the cluster volume and retains it for the backup retention period. They are continuous and incremental, so I can quickly restore to any point within the backup retention period between 1 and 35 days. In addition, I can take manual snapshots and move them across regions if needed.
There is more
Amazon Neptune is coming with many features, and I still need to check each of them, but on my radar, I have the following:
- Export: export data to S3.
- Streams: capture changes to a graph as they occur.
- Full-text search: based on Amazon OpenSearch Service and Lucene query syntax.
Conclusion
In this post, I have described the basics. As I learn more, I will write more, especially on the extra features. As a serverless enthusiast, it is a step back because of all the setup required to work with Neptune. For example, configure a Jupiter notebook to see your graph in a UI. Then, if you want to have a full-text search, you have another cluster with OpenSearch service, and of course, I need to configure VPC, subnets and security groups. I define it as a legacy world, but Neptune seems a powerful tool to solve complex networking and recommendation use cases. I will for sure learn more and post more about my experience.