
API Gateway to a Lambda function using Lambda proxy and non-proxy integration, with OpenAPI specs

I have spent some time with API Gateway over the past months to build a UI's backend. In this post, I will go through the experience with API Gateway and how to build a simple CRUD system protected by a Custom Lambda Request Authorizer.
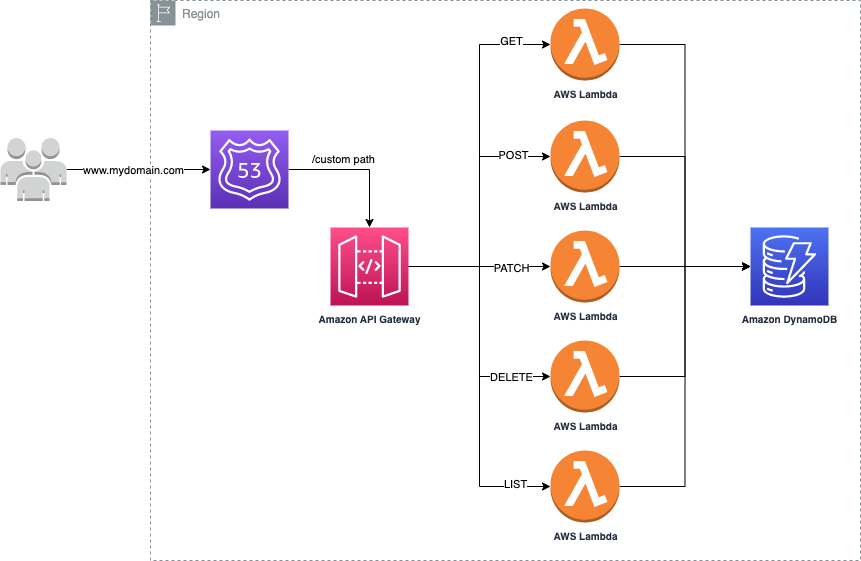
As you can see from the image above, the backend is made of a Route53 Record A that points to my custom domain.
RecordSet:
Type: AWS::Route53::RecordSet
Properties:
HostedZoneId: !Ref Route53HostedZoneId
Name: !Ref Route53DomainName
Type: A
AliasTarget:
HostedZoneId: !Ref CustomDomainHostedZoneId
DNSName: !Ref CustomDomainName
View the complete File on GitHub
Custom domain names are more straightforward and intuitive URLs that I can provide to my API users or, in my case, to the frontend person instead of the random API identifier. The main advantage is that I can decouple the custom domain creation with the API Gateway creation, allowing me to avoid changing the UI if I need to drop the API stack for any reason.
The custom domain is mapped to my API using base path mapping. The base path name must be provided as part of the URL after the domain name, and the value must be unique for all mappings across a single API. I could access multiple APIs behind one custom domain by adding the base path name instead of deploying various custom domains or referencing multiple random API identifiers.
CustomDomainName:
Type: AWS::ApiGateway::DomainName
Properties:
RegionalCertificateArn: !Sub "arn:aws:acm:${AWS::Region}:${AWS::AccountId}:certificate/${CertId}"
DomainName: !Ref DomainName
EndpointConfiguration:
Types:
- REGIONAL
Tags:
- Key: Name
Value: !Ref AWS::StackName
- Key: env
Value: !Ref StageName
MyApi1Mapping:
Type: AWS::ApiGateway::BasePathMapping
DependsOn: CustomDomainName
Properties:
RestApiId: !Ref MyApi1
DomainName: !Ref CustomDomainName
BasePath: 'api1'
Stage: !Ref StageName
MyApi2Mapping:
Type: AWS::ApiGateway::BasePathMapping
DependsOn: CustomDomainName
Properties:
RestApiId: !Ref MyApi2
DomainName: !Ref CustomDomainName
BasePath: 'api2'
Stage: !Ref StageName
View the complete File on GitHub
The API Gateway will have the basic resources:
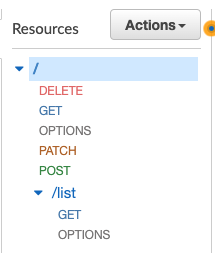
Each resource integrates with single functionality Lambda Function. Inside each Lambda function, some logic and operation with DynamoDB as storage. Remember that a single functionality Lambda follows the KISS principle and makes the Lambda function easy to maintain and to understand, without mentioning other benefits like they can scale differently, have different configuration settings and much tighter security rules.
Things are getting interesting in the Lambda integration part. The simplest is the proxy integration, where I set the integration's HTTP method, the integration endpoint URI to the ARN of the Lambda function invocation action of a specific Lambda function, and grant API Gateway permission to call the Lambda function on your behalf. When a client submits an API request, API Gateway passes the raw request as-is to the integrated Lambda function.
In Lambda non-proxy integration, I must specify how the incoming request data is mapped to the integration request and how the resulting integration response data is mapped to the method response. It means that nothing will work out of the box because if, for example, the Lambda input request uses some SDK API Type, this will be incompatible with the input request. Furthermore, if the Lambda function code returns a different status code, they now do not work anymore. So everything is 200 unless I play around with regular string expressions.
Before going into the Lambda non-proxy integration configuration, I wanted to secure access to my API by building a fine-grained authorization. Because of this, I need to use an API Gateway custom authorizer. There are two types of custom authorizers: TOKEN and REQUEST, and the main difference if the event object that Lambda function is receiving. I used REQUEST because this contains all the information needed, like headers, query string and other information.
The Lambda Request Authorizer has my custom logic to verify the JWT and, from there, get the claims and check if the user is allowed or not to execute a particular action.
The code (Rust) could look like this:
use aws_lambda_events::apigw::{
ApiGatewayCustomAuthorizerRequestTypeRequest, ApiGatewayCustomAuthorizerResponse, ApiGatewayCustomAuthorizerPolicy, IamPolicyStatement,
};
use lambda_runtime::{run, service_fn, Error, LambdaEvent};
use serde_json::json;
#[tokio::main]
async fn main() -> Result<(), Error> {
tracing_subscriber::fmt()
.with_ansi(false)
.without_time()
.with_max_level(tracing_subscriber::filter::LevelFilter::INFO)
.init();
run(service_fn(function_handler)).await
}
pub async fn function_handler(event: LambdaEvent<ApiGatewayCustomAuthorizerRequestTypeRequest>) -> Result<ApiGatewayCustomAuthorizerResponse, Error> {
// do something with the event payload
let method_arn = event.payload.method_arn.unwrap();
// for example we could use the authorization header
if let Some(token) = event.payload.headers.get("authorization") {
// do something with the token
// my custom logic
return Ok(custom_authorizer_response(
"ALLOW",
"some_principal",
&method_arn,
));
}
Ok(custom_authorizer_response(
&"DENY".to_string(),
"",
&method_arn))
}
pub fn custom_authorizer_response(effect: &str, principal: &str, method_arn: &str) -> ApiGatewayCustomAuthorizerResponse {
let stmt = IamPolicyStatement {
action: vec!["execute-api:Invoke".to_string()],
resource: vec![method_arn.to_owned()],
effect: Some(effect.to_owned()),
};
let policy = ApiGatewayCustomAuthorizerPolicy {
version: Some("2012-10-17".to_string()),
statement: vec![stmt],
};
ApiGatewayCustomAuthorizerResponse {
principal_id: Some(principal.to_owned()),
policy_document: policy,
context: json!({ "email": principal }), // https://github.com/awslabs/aws-lambda-rust-runtime/discussions/548
usage_identifier_key: None,
}
}
Except for the custom logic, the Lambda Request Authorizer will Deny or Allow the request.
API Gateway allows me to cache the response for the authorizer. The authorizer is usually configured to use the Authorization header as an identity source (for example, a header \"Authorization\" with value 123). Then this policy is cached and used for all other requests with the same identity source. I could disable the cache, but it comes with drawbacks, and one of them is the added latency of invoking the authorizer multiple time for the same request.
This means that because the Authorization header is the same, requests made to different endpoints or methods would result in the same cached authorizer response. This does not work if the user has separate permission based on the operation of the API.
To solve this problem without disabling the cache, I can configure the Context variables and the Authorization header. Specifically, I can use the \"$context.httpMethod\" and \"$context.resourceId\" variables which describe the method and specific resource to which the request was made. This means that even if the Authorization header is the same, requests made to different endpoints would result in API Gateway invoking the Lambda authorizer to generate a new response for those requests. With this approach, I would then allow modular access to methods because the resource policy can be adjusted to use these variables to only grant access to that resource. I can also implement logic to provide more access based on the method and resource to the request.
MyApi:
Type: AWS::Serverless::Api
Properties:
Name: !Sub ${AWS::StackName}
StageName: !Ref StageName
...
Auth:
AddDefaultAuthorizerToCorsPreflight: false
Authorizers:
jwt:
FunctionArn: !Ref JwtArn
FunctionPayloadType: REQUEST
Identity:
Context:
- httpMethod
- resourceId
Headers:
- Authorization
JwtConfiguration:
issuer: ....
audience: .....
DefaultAuthorizer: jwt
ResourcePolicy:
CustomStatements: [{
"Effect": "Allow",
"Principal": "*",
"Action": "execute-api:Invoke",
"Resource": "execute-api:/*/*/*"
}]
Tags:
Name: myapi
Env: !Ref StageName
Because there is a cache involved, there is no one way that fits all, so how long should I cache the API Gateway authorizer response? It depends on the type of application, for example, internal or public application, traffic and many other requirements. There is no way to invalidate a single custom authorizer response, so I should live with some stale data or set a very low-level cache time. In case of a massive breach, there is a way to flush all using the flush-stage-authorizers-cache
Initially, when I built the UI backend, I used only Lambda proxy integration, and with no effort, after a few hours, it was all up and running. While testing and prototyping, I asked myself how I could save the user that did the operation in the database.
When using a custom authorizer, there is a way to inject additional context into the request and pass the context object from a Lambda authorizer directly to the backend Lambda function as part of the input event.
context: json!({ "email": principal }), // https://github.com/awslabs/aws-lambda-rust-runtime/discussions/548
It was naive of me to think that this was a supported feature because it turned out that this work only for:
When using API Gateway, the HTTP API type lacks many other essential features, so many people always point to the REST API type for a reason. Unfortunately, the REST API did not get much love from AWS in the past years, and not much has improved in terms of functionalities. For example, I want to pass the context object from a Lambda authorizer directly to the backend Lambda function as part of the input event. In that case, I need to leave the comfort zone of proxy integration and go into the wild world of non-proxy integration.
In Lambda non-proxy integration, I must specify how the incoming request data is mapped to the integration request and how the resulting integration response data is mapped to the method response and here I met my new tedious and error-prone best friend Velocity Template Language also known as VTL. There would be nothing wrong with VTL if the AWS experience were better, like with some auto-complete tool or a way to validate the code quickly, something like MappingTool
While you can find many examples of deploying API Gateway on ServerlessLand, this is only part of the full story. There is a lack of documentation or full examples and so as Eric Johnson said:
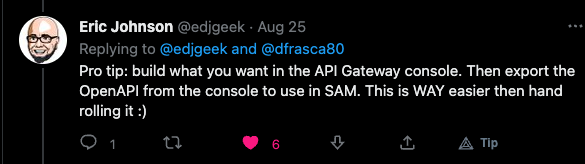
I have followed his advice and built a complete CRUD example after giving up doing it in pure CloudFormation or other tools.
Before showing you the entire code, I wish to be aware of a few things because the export does not work out of the box:
- I must clean it up
- I needed to add Fn::Sub: all around
- I needed to remove the x-amazon-apigateway-policy because it generated a Circular dependency
- I needed to remove the info section
These are tiny things, but I wished for better documentation/examples, which is why this article is.
A fully CRUD template for an AWS API Gateway with OpenAPI specs that follow this architecture:
This would result in two files:
The template is standard. I create the AWS::Serverless::Api point to the OpenAPI spec file:
DefinitionBody: # an OpenApi definition
'Fn::Transform':
Name: 'AWS::Include'
Parameters:
Location: './openapi.yaml'
OpenApiVersion: 3.0.3
And deploy each Lambda function for each resource of my API.
While the template above is configured to use Rust
Globals:
Function:
MemorySize: 256
Architectures: ["arm64"]
Handler: bootstrap
Runtime: provided.al2
Timeout: 29
Environment:
Variables:
RUST_BACKTRACE: 1
RUST_LOG: info
The OpenAPI spec file is agnostic and can be used for any runtime:
The exciting part of the template OpenAPI spec file is the x-amazon-apigateway-integration for the POST and PATCH.
I used the non-proxy integration for those two resources, so I have to map my request and my responses.
The Integration request is:
#set($allParams = $input.params())
{
"body" : $input.json('$'),
"params" : {
#foreach($type in $allParams.keySet())
#set($params = $allParams.get($type))
"$type" : {
#foreach($paramName in $params.keySet())
"$paramName" : "$util.escapeJavaScript($params.get($paramName))"
#if($foreach.hasNext),#end
#end
}
#if($foreach.hasNext),#end
#end
},
"stage-variables" : {
#foreach($key in $stageVariables.keySet())
"$key" : "$util.escapeJavaScript($stageVariables.get($key))"
#if($foreach.hasNext),#end
#end
},
"auth" : {
"email" : "$context.authorizer.email"
}
}
Making the Lambda input request look like this:
{
"auth":{
"email":"a@a.com"
},
"body":{
"key":"my_id",
"property1":"something"
},
"params":{
"header":{
"Accept":"*/*",
"Accept-Encoding":"gzip, deflate, br",
"Authorization":"Bearer xxxxx",
"Content-Type":"application/json",
"Host":"something.com",
"User-Agent":"PostmanRuntime/7.29.2",
"X-Amzn-Trace-Id":"Root=1-4343434-15fc477270bcvce21c1bcc983d",
"X-Forwarded-For":"X.X.X.X",
"X-Forwarded-Port":"443",
"X-Forwarded-Proto":"https",
"X-Restrict-Header":"ca2sdfsd0-34ds-407c-b379-7fg3re0efb5"
},
"path":{
},
"querystring":{
}
},
"stage-variables":{
}
}
The Integration response should follow the Lambda logic.
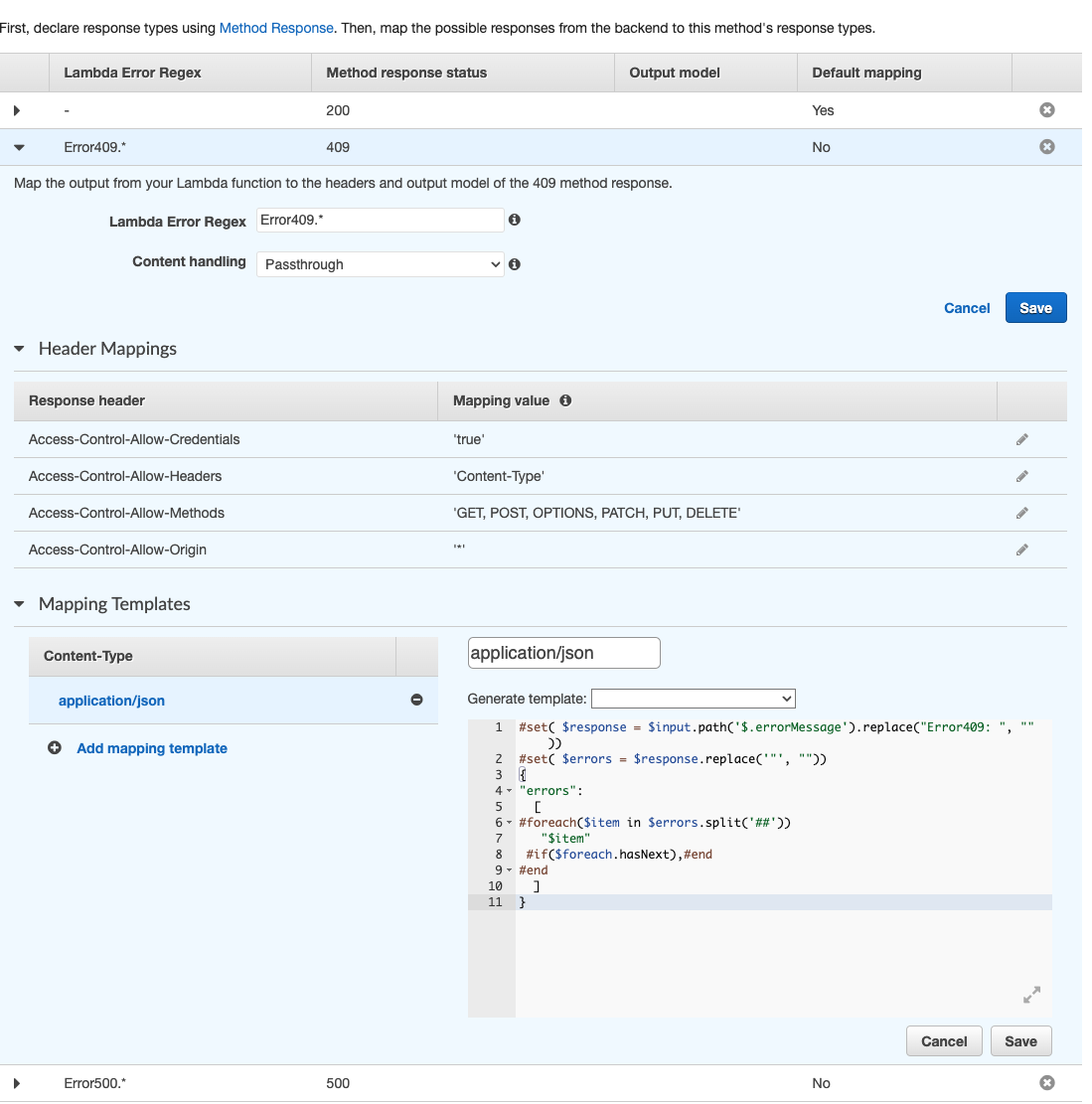
Here you need to map all the status code that the Lambda return, for example, 200, 404 and so on.
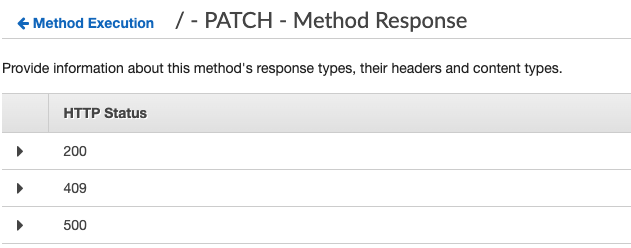
By default, the primary response is with status code 200. However, I must use the Lambda Error Regex if I wish to return like my template above 409 or 500. This means I need to throw an Error with a string containing some KEY that I can use with the Lambda Error Regex based on the errorMessage string of the Lambda error.
Inside my Lambda code, I throw an error that starts with a specific string:
- "Error409: something has happened"
- "Error500: something exploded"
Now with some VTL replacements, I intercept the string and build my custom response for the UI.
#set( $response = $input.path('$.errorMessage').replace("Error409: ", ""))
#set( $errors = $response.replace('"', ""))
{
"errors":
[
#foreach($item in $errors.split('##'))
"$item"
#if($foreach.hasNext),#end
#end
]
}
Conclusion
This article aims to create a small guide that covers some common scenarios (CRUD) and to have them all in one place instead of the hello world example that would require finding sparse information all over the internet.
This example is incomplete and will surely not cover all the needs out there, like throttling or API keys, but extending it with some specific needs should be easy.
I have covered the following topic:
- Deploy a custom domain front of the API to decouple the client (in my case, UI) and API
- A complete API CRUD example using OpenAPI spec
- How to use a Lambda Request Authorizer that injects additional context into the request and passes the context object from a Lambda authorizer directly to the backend Lambda function as part of the input
- Mix in one API Lambda integration proxy and non-integration proxy
- Some VTL to transform the input request and the lambda response with multiple status codes.
I hope you like it. For any questions, you find me on Twitter