




Serverless applications are becoming more common, and more people migrate their container applications. So I see a pattern emerging talking around with people in different countries, and this post is just a summary of things that I have been blabbering about for a while.
Migrations
Serverless applications at first could be seen as complex, especially if you spent your entire life working on different setups. So the first step is to understand how your system works and decompose it. You can find a lot of this matter like decomposing by:
- business capability
- subdomain
- transaction
Hopefully, your application is already using this separation. After this point, you need to decide how to move to the serverless design effectively, and you can opt for:
- Completely replacing the system.
- Shadowing allows you to run two separate versions of the application.
Both have pros and cons and you could mix them based on the needs. A good solution is to incrementally replace specific pieces of functionality with new applications and services, creating a façade/proxy that intercepts requests and redirects requests either to the legacy application or the new services.
The fat Lambda
It has been written a lot on this matter, but a fat Lambda is like shift and lifts all your code. To make it easier, a fat Lambda will do too many things.
What is too big? I do not want to get into this discussion because it is the same as TDD or not TDD. My angle is for increasing the application's maintainability, observability, and onboarding time.
A possible fat Lambda
I will show a random code to give you an idea.
class WeekFactory {
public day(input): Day {
switch (input.day) {
case "Monday":
return new Monday(input);
case "Tuesday":
return new Tuesday(input);
.....
case "Sunday":
return new Sunday(input);
}
}
A factory creates an object but lets the subclass decide which class to instantiate. Imagine that inside each subclass, there is a logic-based configuration, and each Day returns a type of Day that varies independently.
context = new Context(input);
context.doSomething();
interface Strategy {
doSomething(input);
}
class StartegyA : Strategy {
doSomething(input)
}
class StartegyB : Strategy {
doSomething(input)
}
This code is very generic but imagines a use case like:
The Monday factory loads the StrategyX based on input and dynamic config conditions.
If it is Sunday factory loads the StrategyX based on input and dynamic config conditions and also check if it is the third Sunday of the month.
As you can see, each Day object can be something different each time.
Is this is what we consider too fat? There is nothing wrong with this code in one Lambda function, but my angle is for increasing the application's maintainability, observability, and onboarding time.
Move it to Step Function
I just added two days to keep the image clear for the explanation.
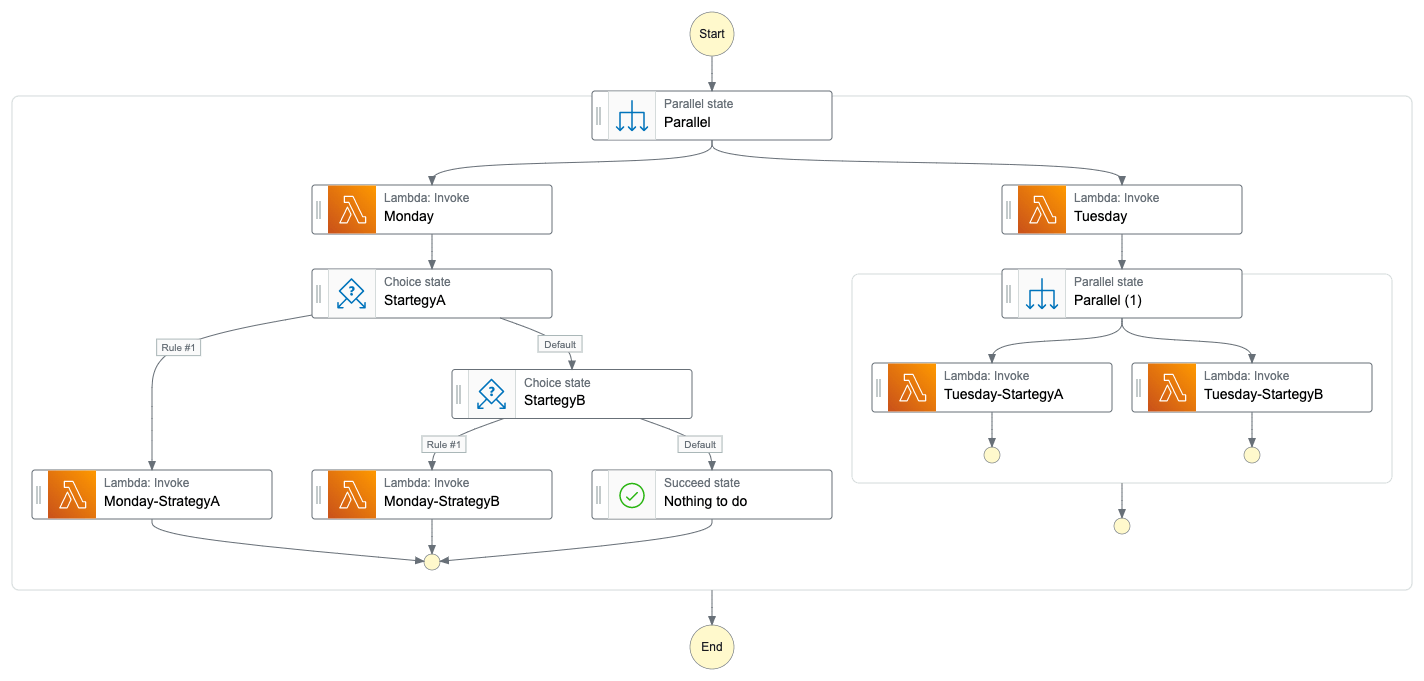
With the Step Function, we can build a flow in multiple ways. I can use the Parallel state, sending the same request to all the Lambda functions, and each of them will take care to discard the event. So, for example, if the input contains Monday, all the other Lambda like Tuesday will discard the request.
You can add Choice state and avoid triggering Lambda functions and have a clear path.
I have added both because it is up to you which one you want to use.
Benefits
If you are thinking "Too many Lambda functions", you are not alone because now you moved from, for example, one Lambda function to seven Lambda functions plus all the strategies, but what is the problem with this?
I gained much more:
- Observability - I can identify individual service responsibilities without understanding the details.
- Maintainability - I have removed boilerplate code like if, switch and more.
- Extensibility - I can now extend a branch adding a specific logic, or strategy without worrying about the base flow.
- Reduce onboarding time - I can use the Step Function flow that indicates business logic without worrying about going inside the code, reading unit tests, and explaining why or why not using a factory or a strategy pattern.
Conclusion
It took more configuration (primarily Infrastructure as Code) to setup the Step Function than just having a lambda. Moving to this design is not without friction because you need to know the limitation of the Step Function service and test the application to see if some new behaviour exists. Nevertheless, it will force you to decouple your code, reduce code ownership, and reduce the complexity of your application benefiting from many built-in features provided by AWS Step Function like error condition handling, input and output processing, try/catch and so on.