
Serverless cache

Did I invent a serverless cache service? I will answer this question later on.

I recently got interested in serverless multi-region configuration, and it turned out there are many AWS services that will help you to achieve a multi-region like:
- CloudFront failover configuration
- Route53 routing policies
- DynamoDB global tables
I am sure I miss many more, but while building a prototype application, I started to consider how to cache data. The most famous in-memory services are:
- Amazon DynamoDB Accelerator (DAX)
- Amazon ElastiCache
DAX or a similar in-memory cache must be used if there is the need to generate a response in microseconds. DAX, for example, increase throughput for heavy read applications and reduces operational complexity because its usage is transparent with DynamoDB.
Regardless of the use cases for in-memory cache, I mentioned in the post how Amazon DynamoDB fit in a multi-region scenario, it is not possible to use DAX because it replicates itself within the same region. Therefore, to achieve multi-region, I must deploy a DAX cluster in each region and create some replication and failover mechanism.
I am sure the scenario I will describe is not the same for everybody but bear with me.
Imagine two teams with different accounts. Each group could or could not implement their caching logic and cache something in CloudFront and something in some in-memory service.
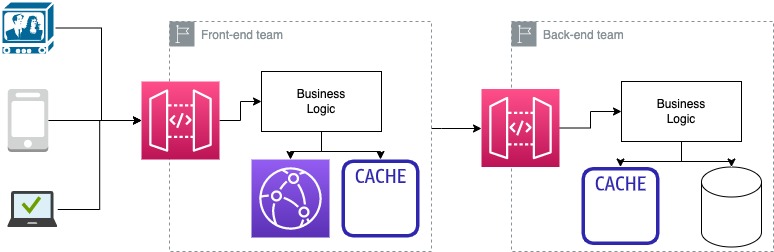
I asked myself if I could go around and simplify the architecture cross-team, and I came up with the idea to use DynamoDB global tables in conjunction with CloudFront.
It is already evident that it cannot be a one to one comparison between an in-memory service and CloudFront. However, based on the requirements and trade-off, I think it could be a good alternative, mainly because fewer operational tasks are involved.
Caching with CloudFront and DynamoDB
Cache, in very simple words, is used to speed up the application and avoid to stress the application services requesting multiple times the same thing.
My goal is to find an alternative way to centralise cache across teams and remove the need for in-memory clusters. Let's see a few examples:
- CloudFront as alternative
- DynamoDB as alternative
The results of this serverless cache will have the following flow:
CloudFront as alternative
If the front-end team request multiple times, for example, an object with ID=2, to a back-end team, this team has two options:
- each time, make a query to its data source
- query once and put it in the cache, and return the object from the cache
A good practice is to cache for a specific time the response from the data source and return this version without overwhelming the data source and keep it ready, maybe for other operations, even if this means setting a very low TTL.
There is always a network latency between the front-end team and back-end team, so the front-end team could also decide to cache the already cached response from the back-end team on his side. Usually, this is made for two reasons:
- help the back-end team to scale more avoid unnecessary requests
- avoid the extra latency to call the back-end team and be more responsive to the end-user.
The front-end team maybe decide to cache all the responses from the back-end into an in-memory service and apply the TryGetValue pattern.
A TryGetValue pattern will try to retrieve the object from the cache, and if there is a miss will go to the origin and save it into the cache.
The front-end team can also decide:
- they do not need micro milliseconds access to data
- they do not want to maintain an in-memory cluster
So their trade-off is to use CloudFront and store everything there closer to the user and live with the idea that if they need to invalidate or overwrite a cache key, this is not immediate like the in-memory cache. Eventual consistency trade-off.
DynamoDB as alternative
DynamoDB is fast, and the typical latency is in the order of 10ms response. Moreover, thanks to its on-demand capacity, I don't need to worry about the uncertain volume of requests, while with an in-memory cluster, I need to provision the correct size and scale up and down if needed. Thanks to global tables, DynamoDB propagates the write to the other replica tables in the different regions. In a multi-region design, you can query closer to the end-user.
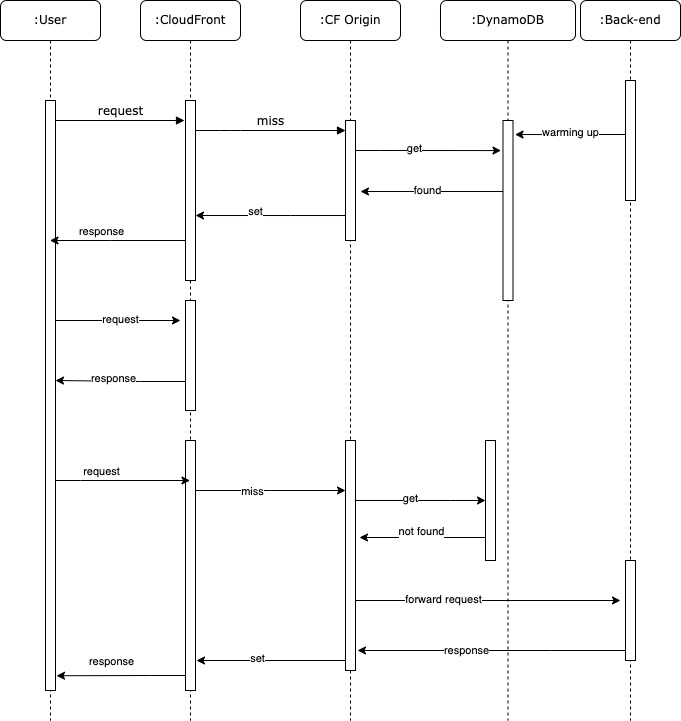
In a typical application scenario, if a user generates a request and it is not present in the cache, the request will reach the origin where it will be retrieved. This is the worst-case scenario for an end-user experience. However, there is the concept of warming up the cache. Essentially it will put the items in the cache before end-user requests resulting in a better experience because now the information is served from the cache.
The cache in this project is CloudFront, and the warming up flow will require DynamoDB as the middle man between the end-user and the origin.
As a team, I can warm up the cache in multiple ways:
- build a crawler that will go through my website pages and hit the origin when items are not in the cache
- each team implement their logic to call CloudFront to generate a missing key and call the origin
- create a serverless cache service
The serverless cache service can be used in a single and multi-region setup. However, with multi-region, the struggle with the cache is more evident because currently, the in-memory services provided replicate themself in the single region.
A multi-region infrastructure will require the following:
- CloudFront failover configuration
- Route53 Latency routing
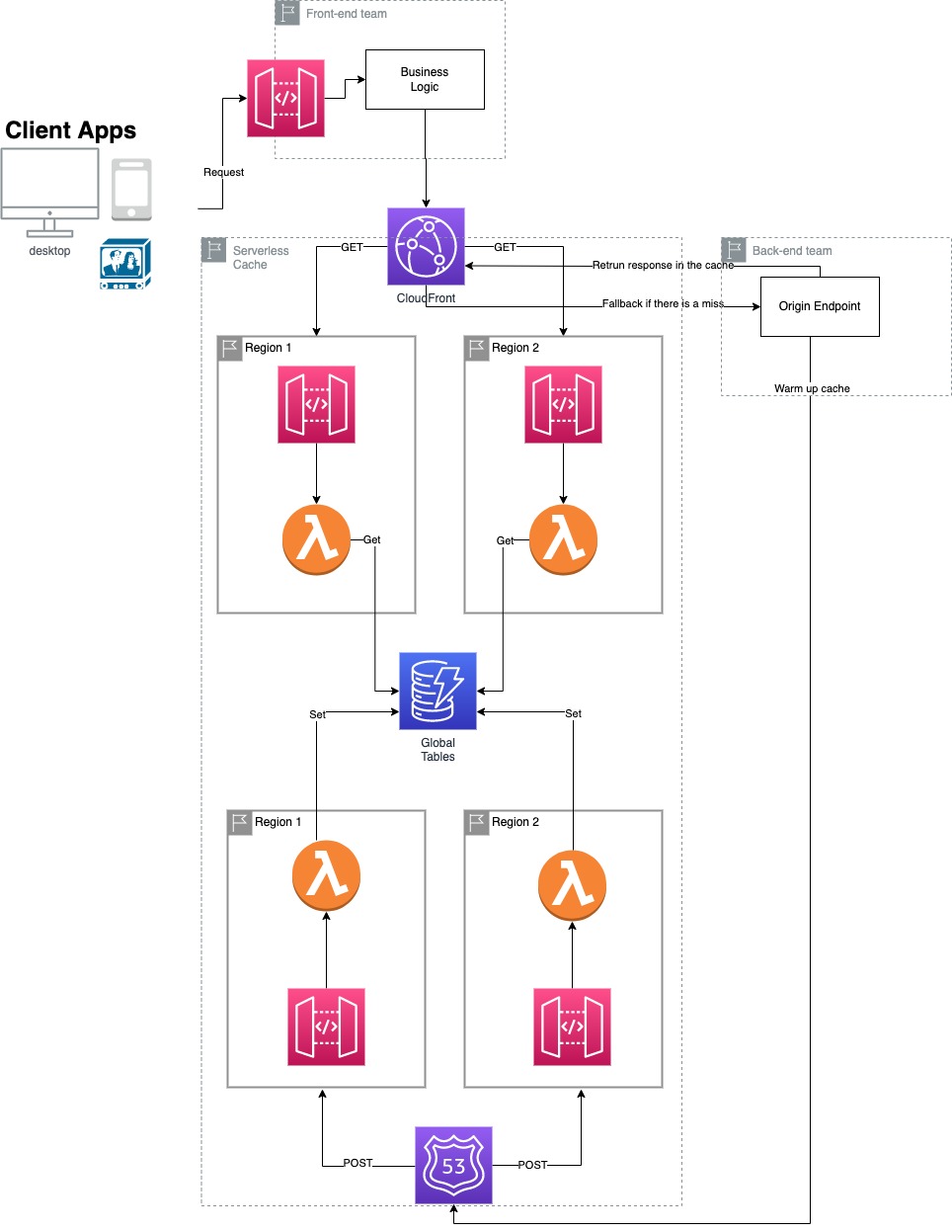
The cache service is made of an endpoint with two routes:
- GET - TryGetValue pattern
- POST - warming up the cache
CloudFront is used in front of the cache service. CloudFront origins will point to the APIGW endpoint, and because it is multi-region, each origin will be in a different AWS region.
The POST route is used to warm up the cache, and this will require:
- APIGW custom domain
- Route53 latency routing pointing to the APIGW custom domains.
Route53 will redirect the request to the following best latency endpoint if one of the endpoints goes down.
How is DynamoDB used?
DynamoDB is used only for the warming cache scenario without stressing the origin with many requests. Instead of bombarding the origin, I can now emit events, write into DynamoDB, set a TTL and lookup CloudFront asynchronously because the TryGetValue pattern will cache directly into CloudFront.
In theory, with the TryGetValue pattern, I could remove all the DynamoDB parts. However, imagine I want to warm up ten thousand or 100 thousand items. I can do this asynchronously, spreading the queries without risking consuming all the resource capacity of the application. Using the TryGetValue flow instead, I will run all the requests against the entire system. Having the async option, I can also warm up the cache by listening to events gaining more flexibility.
Using in-memory cluster
An in-memory architecture requires:
- A cluster in each region
- Patching and managing the clusters
- Synchronisation system to move data across the region
Optionally for processing:
- APIGW + Lambda inside the VPC with relative limitations
- ECS Cluster and another cluster to deploy and maintain.
- Application Load Balancer instead of APIGW that invokes an AWS Lambda function.
In this schema, for example, I consider a front-end team that must cache data for their apps and, when there is a miss or something else, will request the data to a back-end team that will cache internally also their data.
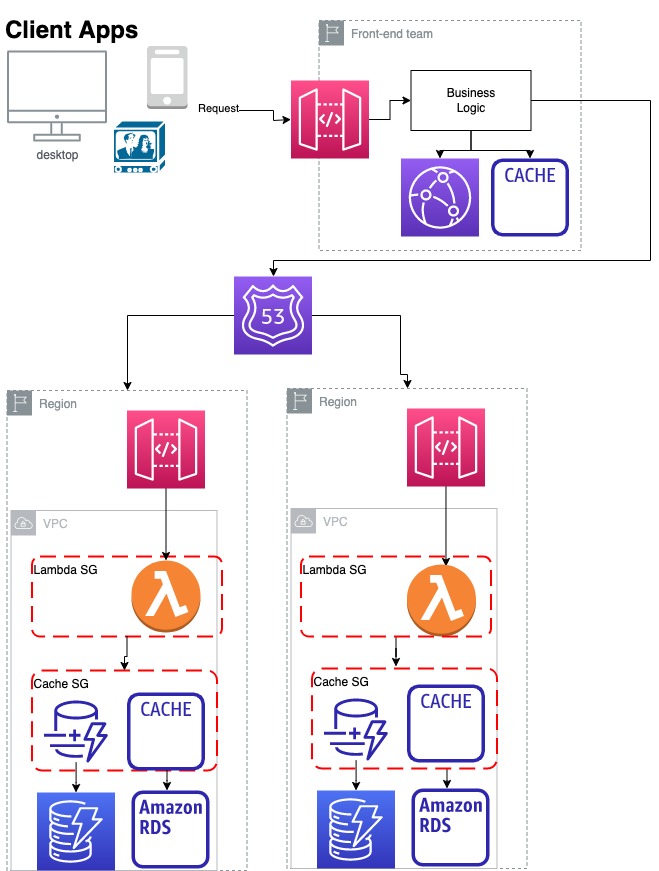
Serverless way
With CloudFront and DynamoDB, I have simplified the operational tasks for maintaining an in-memory cluster, centralised the cache and found an acceptable alternative way to use a cache cross-team and closer to end-users.
Considering that the applications will call the endpoint in the front-end team anyway, now, with a cache key policy shared cross-team, the response time will be just network latency to reach the CloudFront, which is pretty much the same as calling the back-end team. Of course, this is not covering all the cases in the world, but I pretty much free up the resources of the back-end team, cutting the majority of the request to them, which would be just a waste of resources to load data from the cache. With less unnecessary traffic, I have now resources/quotas to serve requests that do not require cache.
Some words about the PoC
All the code of this PoC is available on my GitHub repository, where you can see the concepts and templates to deploy the infrastructure. Because it is a PoC, I took the liberty to omit something like:
- Amazon Route 53 Latency policy route front of Amazon API Gateway
- I assume a custom domain with CloudFront is used
The deployment is a bit cumbersome without them, so some manual configuration is needed, but the templates are there.
You can find the template for Amazon Route 53 Latency policy route in front of Amazon API Gateway in Serverlessland. The latter is easily editable, adding some changes to the current template:
##########################################################################
# Parameters #
##########################################################################
Parameters:
ApiPrimaryEndpoint:
Type: String
ApiSecondaryEndpoint:
Type: String
AlternateDomain:
Type: String
... omitted for readability
##########################################################################
# CloudFront::Distribution #
##########################################################################
CloudfrontDistribution:
Type: AWS::CloudFront::Distribution
Properties:
DistributionConfig:
....
Aliases:
- !Ref AlternateDomain
ViewerCertificate:
AcmCertificateArn: <your ACM Certificate ARN>
MinimumProtocolVersion: TLSv1.2_2021
SslSupportMethod: sni-only
....
The PoC contains:
- A CloudFront function - fixing the browsers cache behaviour
- Lambda function: set-cache - warming up the cache, adding into DynamoDB with a TTL for expiration, and making the lookup in CloudFront with the same TLL to keep them in sync.
- Lambda function: get-cache - retrieve the data from DynamoDB. If there is a miss, request it directly from the origin and cache it in CloudFront, and as a miss, it is also considered if data in the Dynamodb item is expired but not yet deleted from the DynamoDB Time to Live (TTL).
- Lambda function: origin - simulate the origin back-end team where I simulate a call to a source with a Thread.Sleep and return a JSON
To simulate the TryGetValue pattern, the URL is:
//the origin_url can also be in the header, but for PoC, I put it in the query string.
https://<ideally alias cloud front domain>/cache?key=daniele&origin_url=https://<origin domain>/origin?key=daniele
Warming up the cache, it is a POST to
//https://<route53 custom domain or API endpoint>/set-cache
{
"key": "daniele",
"data": "whatever I want, string, number, json",
"cdnTTL": 120,
"clientTTL": 10
}
It will add the content into DynamoDB, setting the TTL to the record with the same value as the CDN (cdnTTL). I can control the cache in the CDN and Browser with the Cache-Control headers.
Cache-Control: "public, max-age=10, s-maxage=120;".
Who is setting the cache could be in charge of the time to live. The "max-age" directive tells the browser how long the response should be cached in seconds, while the "s-maxage" directive is for CloudFront. If you want to know more, please read here.
Test results
The code in the origin Lambda adds a random delay from 20ms to 1s to simulate some calls. So this part does not add much value. Nevertheless, I run 1K RPS with random keys resulting in 1K RPS miss and 1K RPS requests to the origin.
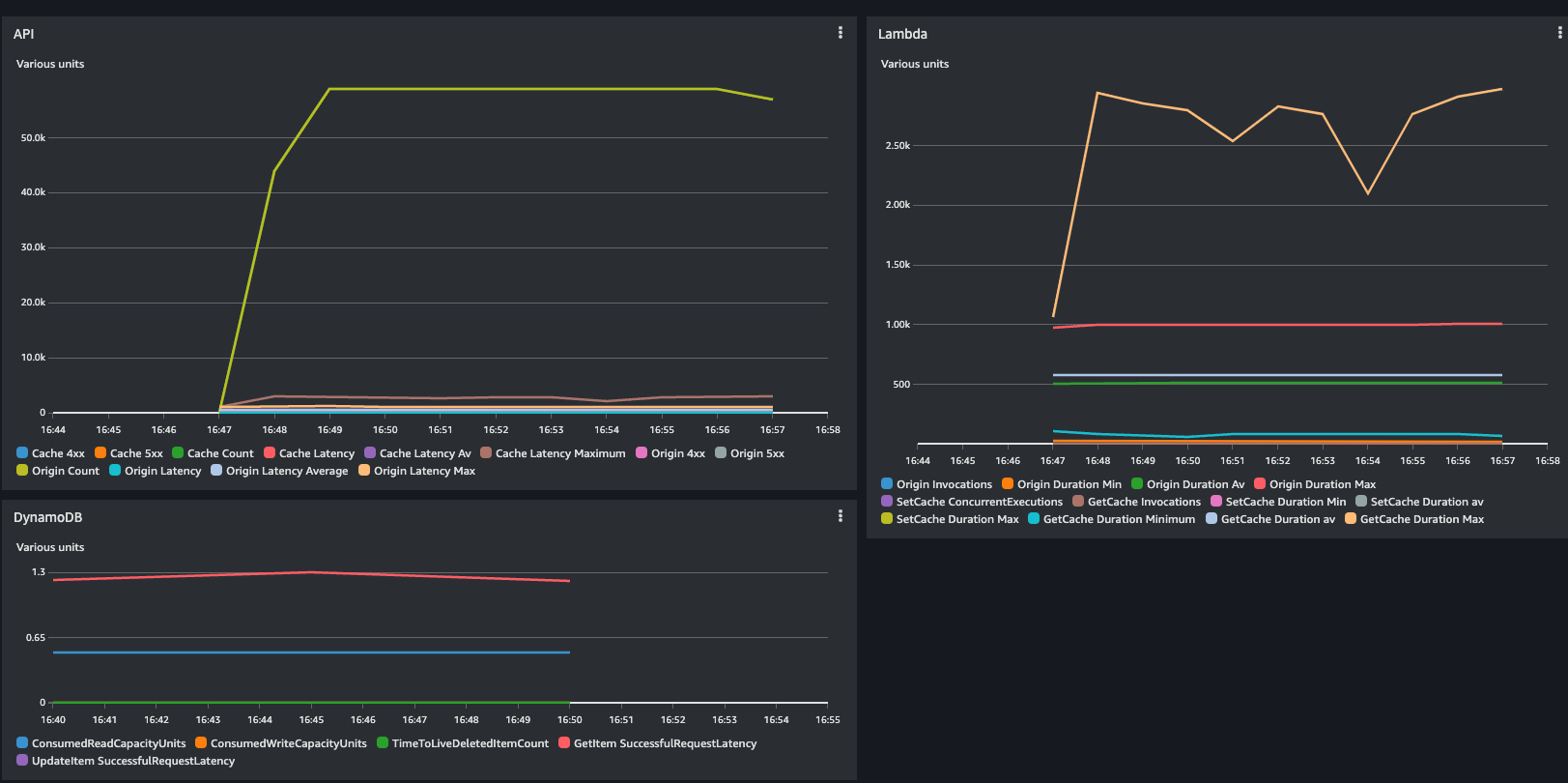
Now I have more or less 600K warmed keys in CloudFront, and I can simulate the steps where the application will retrieve them from the edge.
What I can see is that now the back-end did not receive a call as expected, and the response time is just network latency:
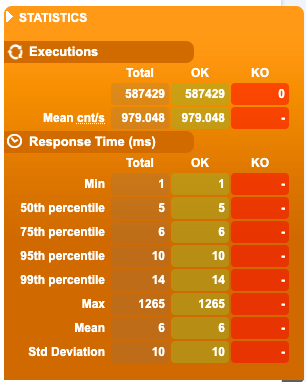
This test is one of my points. Using CloudFront, we have now saved 600K requests to the back-end, which was most likely serving all the requests from their in-memory cache for the same more or less latency.
Not all that glitters is gold
As I mentioned at the start, this design will not apply to all use cases, and this section will highlight a few.
What is the consistency model of the application? Can I serve stale data? This is a game-changer for many use cases, so this idea with CloudFront and his slow evictions cannot apply. But maybe only DynamoDB could be an option and manage the TTL of the records in other ways (Scan, Delete or other application logic)
ElasticCache offers more data structure than DynamoDB and larger objects. DynamoDB has a max size of 400KB. This could be a limitation during the warming up of the cache. Moreover, if you want to do it asynchronously, services like SQS and SNS have a limit of 256KB, which is also to consider. I can go around with S3 or synchronously APIGW to Lambda, but the 400KB limit still applies.
If I can have trade-offs on using DynamoDB, maybe I can consider two other options:
- Removing completely DynamoDB from the architecture and using only the TryGetValue pattern
- Replacing DynamoDB with S3 as warming up use case, using the S3 Multi-Region Access Points
In this PoC, I did not protect the access of the content in CloudFront. CloudFront provides several options for securing content that it delivers. It is important also to consider this part, and because of this, I add some extra readings:
- Serving private content with signed URLs and signed cookies
- Signed cookie-based authentication with Amazon CloudFront and AWS Lambda@Edge
- CloudFront authorization@edge
- Amazon CloudFront Functions
Conclusion
Did I invent a serverless cache service? What do you think?
I am sure I am not the first to get inventive on this, but I think it is an alternative with some trade-offs to consider.
I shift the cost to the CloudFront with this design instead of some in-memory cluster. So it is worth saying the prices vary across geographic regions and are based on the edge location where your content is distributed but by default.
I have minimised end-user latency and maximised bandwidth speed with CloudFront by delivering content from edge locations.
With serverless cache, I do not need to patch, maintain scale up/down, replicate data of my in-memory cluster across regions, and that alone is a considerable saving. Remember, the in-memory cluster does not scale to zero, so you have always some machine running even without usage.
Using the max-age directive should minimise CloudFront costs for data transfer out on things that can be cached inside the user browser because it doesn't have to fetch them from the cache in the edge location. Still, on the other hand, this design lacks a quick/overwrite key invalidation on the CloudFront side.
Everything is a trade-off. The choice is yours.
