
Serverless Challenge: Is scaling achievable using Momento as a cache-aside pattern?
This post has been delayed because of re:Invent2023. Could some announcements impact my architectural decision?
I am talking about the Amazon ElastiCache Serverless for Redis. AWS is empowering us with their services; this Redis serverless version is a testament to that. It may be a partial serverless solution but is a step toward a more efficient and seamless experience.
At first glance, I noticed:
Base price of $90/month/GB + 0.34 cents/GB of data transferred
The capability to autoscale every 10 minutes is not enough for spiky traffic
There is a VPC
After verifying the information, I knew that Momento was the better choice. Momento was introduced in November 2022, and I closely followed them. My application requires caching of nearly everything to safeguard the downstream sources, including DynamoDB and S3.
I have approached Momento explaining my need for caching, and in particular, we looked into a specific case when I needed to cache item sizes over 500KB up to 2MB. During my previous tests with S3 and Redis, I encountered scalability issues which I wanted to minimise as much as possible.
My load test is always the same:
Item cached in the CDN for 3 minutes
Test time 2h
Total requests ~200M
RPS > 10K up to 30K
Each request can load N keys up to 20 or 30, and those references are stored in DynamoDB. If I reach 10K RPS with my APIGW, I could hit the cache with 200K or 300K RPS and at 30k RPS of traffic, almost 1M RPS.
Here is a recent spike with raw objects up to 1MB in size (compression makes it around 100KB)
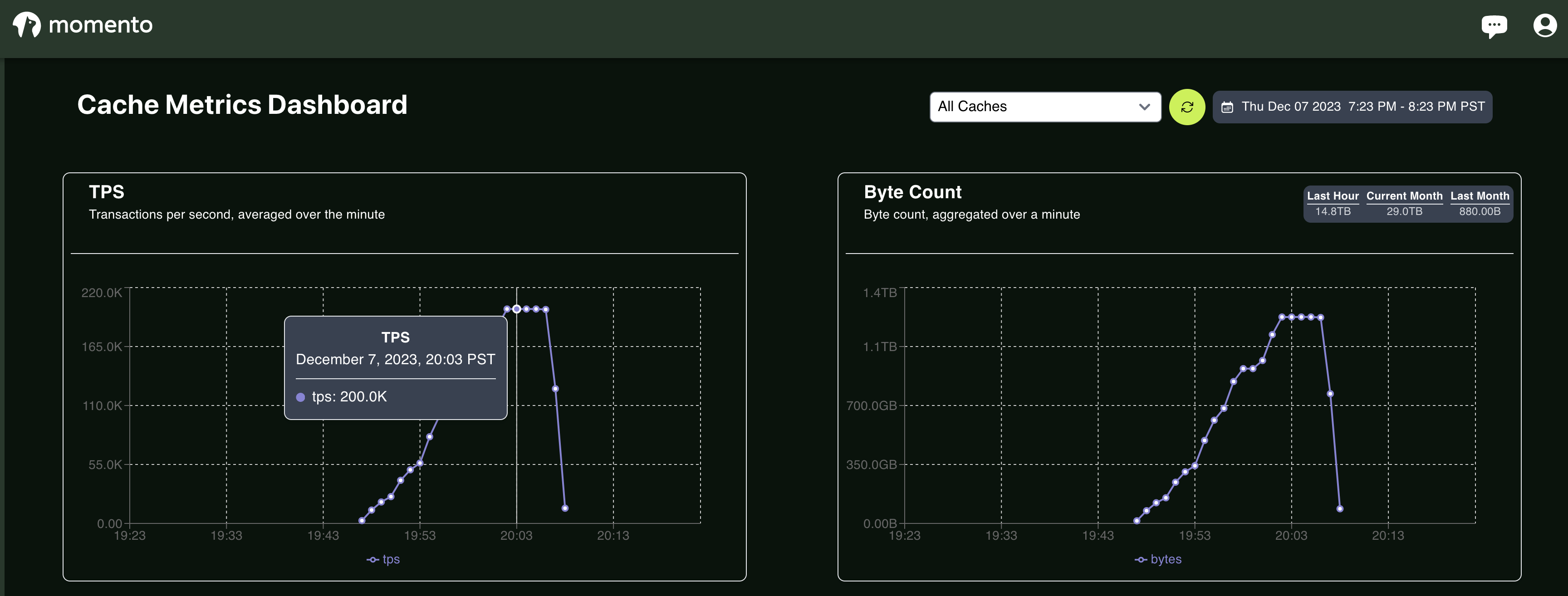
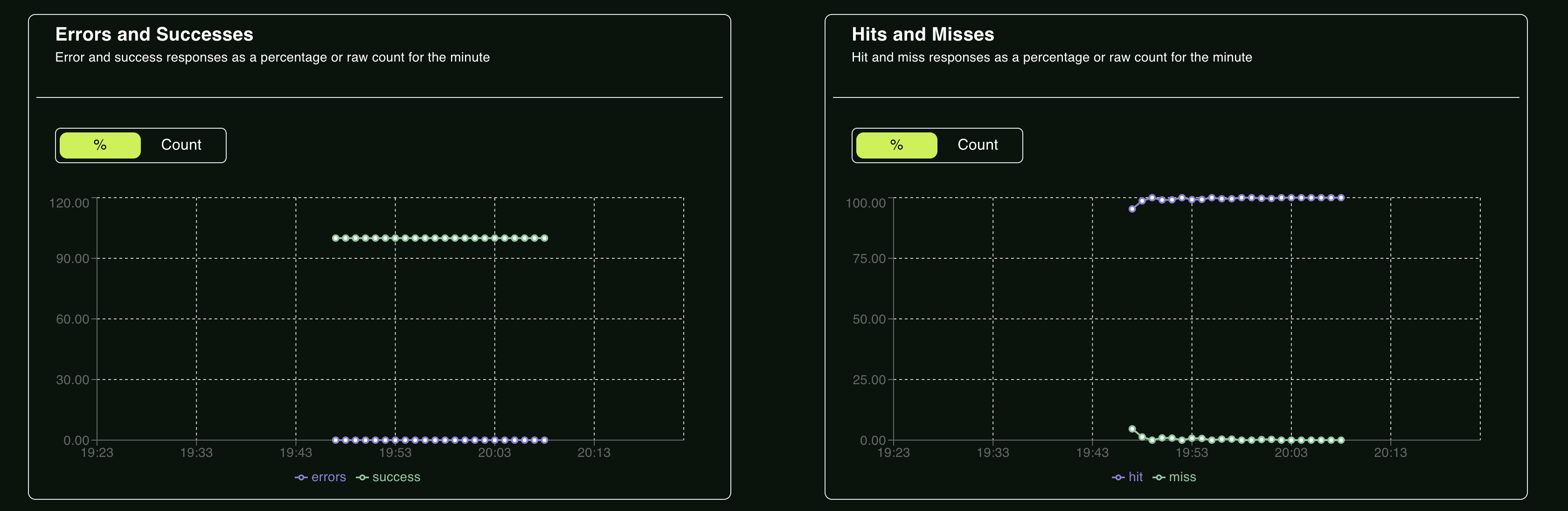
I have achieved remarkable heights without glitches, bringing the error count down to zero and making Momento an outstanding partner you can always rely on.
The test results were quite revealing, showing two areas of significant improvement:
speed
cost
SPEED
At first, I encountered unexpected speed issues, and the results were slower than expected due to the cache size and cross-region access. This access added 20ms to each request, but I could remove it when in the same region. The payload size was a significant challenge, and I knew compression was the solution. Although my initial Rust implementation was unsuccessful, the Momento team stepped in with their expertise and implemented data compression into the SDK, making the solution even more effective.
Momento's expert use of the Zstandard algorithm has resulted in my data being compressed by 90% without any compromise on speed. The latency is comparable to having Redis in the VPC, making data processing faster and more efficient.
The code in Rust to SET/GET a batch of keys in parallel using the compression looks like this:
use crate::dtos::page_item_response::CacheItem;
use async_trait::async_trait;
use momento::response::Get;
use std::sync::Arc;
use tracing::{error, warn};
use typed_builder::TypedBuilder;
#[cfg(test)]
use mockall::{automock, predicate::*};
#[cfg_attr(test, automock)]
#[async_trait]
pub trait CacheService {
async fn get_by_keys(&self, keys:&[String]) -> anyhow::Result<Vec<CacheItem>>;
async fn set_by_keys(&self, items: &[CacheItem]) -> anyhow::Result<()>;
}
#[derive(TypedBuilder)]
pub struct Momento {
cache_name: Arc<String>,
client: Arc<momento::SimpleCacheClient>,
}
#[async_trait]
impl CacheService for Momento {
async fn get_by_keys(&self, keys: &[String]) -> anyhow::Result<Vec<CacheItem>> {
let tasks = keys.iter().map(|key| {
let key: Arc<String> = Arc::from(key.clone());
let mut shared_client = (*self.client).clone();
let cache_name = self.cache_name.clone();
tokio::spawn(async move {
let response = shared_client
.get_with_decompression(&cache_name, key.as_bytes())
.await
.ok();
match response {
Some(Get::Hit { value }) => {
let value: String = value.try_into().ok()?;
serde_json::from_str::<CacheItem>(&value).ok()
}
Some(Get::Miss) => {
warn!("MISSING CACHE KEY: {}", key);
None
}
None => {
error!("MOMENTO get is null {}", key);
None
}
}
})
});
Ok(futures::future::join_all(tasks)
.await
.into_iter()
.filter_map(|result| result.ok().flatten())
.collect())
}
async fn set_by_keys(&self, items: &[CacheItem]) -> anyhow::Result<()> {
let tasks = items.iter().map(|item| {
let item_cloned = item.clone();
let mut shared_client = (*self.client).clone();
let cache_name = self.cache_name.clone();
tokio::spawn(async move {
let cache_item = CacheItem::builder()
.value(item_cloned.value)
.id(item_cloned.id)
.cache_key(item_cloned.cache_key)
.build();
let json = serde_json::to_string(&cache_item).unwrap();
shared_client
.set_with_compression(&cache_name, cache_item.cache_key.clone(), json, None)
.await
.map_err(|e| error!("ERROR - Momento - set_object {:?}", e))
.ok();
})
});
futures::future::join_all(tasks).await;
Ok(())
}
}
COST
Momento pricing is simple:
They charge for $0.50 per GB transferred
Allowing up to 1M+ Operations Per Second (based on your profile)
If I take my Redis cluster NetworkBytesOut metric per month aggregation, I could have a rough cost:
- XTB: $0.50/GB * X,000GB = $xxx
Considering the active compression option, the price can be reduced by about 90%.
Calculating the cost for a similar load using Redis is not straightforward. When operating inside a VPC, there are additional things to consider, such as the Data Processing of NAT Gateways, and the Data Transfer to the Internet, if any.
It's important to note that comparing costs is not as simple as comparing apples to apples. Before drawing any conclusions, I would suggest to get in touch with Momento. They offer significant workflow discounts that can make the cost highly competitive.
In addition to the Serverless Cache that I can use with a Lambda without a VPC, the Momento Cache system offers different connectivity options that can be used inside the VPC, including:
VPC Peering
Private Link
NAT Gateway
Optional Zone Aware Endpoints
From a tenancy perspective, they can offer both shared tenancy as well as dedicated tenancy with varying levels of isolation.
Momento is not just a cache. It offers support for topics which Redis does not. With Redis, to use pub-sub, one needs to configure WebSockets, such as an API gateway or a web server, and then add a layer for authentication. However, with Momento, all of these features are built within a single platform. I can publish and subscribe to topics in a browser using the Momento Web SDK. When data is published to a topic, all subscribers will receive the data, which means browsers can be connected without building server-side code.
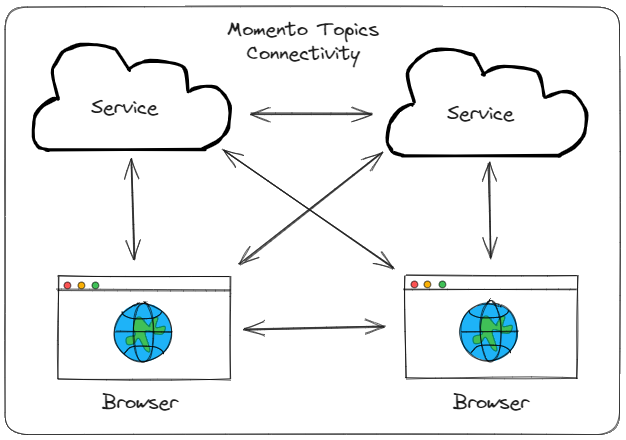
Momento is a true example of a Serverless SaaS service because it offers powerful services, extreme time to market, and reliability. I compare it to services like Lambda regarding power and time to market.
Conclusion
I have found that using compression can significantly reduce costs by up to 90%. While using Momento over Redis resulted in similar p99 latency, the scalability achieved during testing was impressive. Moreover, the cache system did not cause any errors or overflow downstream services, which has given me confidence in my choice. With a generous free tier, an on-demand pricing model that reduces waste between environments and traffic peaks, and the ability to get up and running quickly with no infrastructure setup or maintenance makes Momento a compelling solution for my workload.