
Serverless geolocation
A rust take

This blog post will show you how to integrate a Geo IP Database in a serverless way. A geo IP database is a database of IP addresses with their locations.
There are several free databases available:
Usually, the free version is less accurate, but it is good enough for the proof of concept. For the commercial license, please refer here
I will use MaxMind GeoIP database. There are three versions of the databases:
- Binary Database
- CSV Database
- WebService
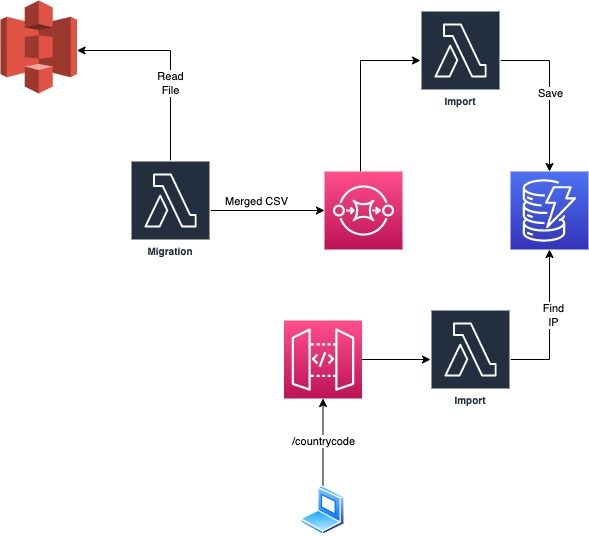
And I have implemented for fun a serverless version for:
The Binary Database version uses this crate maxminddb, while the CSV is a more classic version of code that includes:
- Copy the files into the Amazon S3
- Run the Migration Lambda function
- The Migration Lambda function will merge the CSV into one object and send it to an Amazon SQS
- Amazon SQS will trigger the Import Lambda function
- The Import Lambda function will insert into Amazon DynamoDB
Binary Database
use aws_config::{RetryConfig, TimeoutConfig};
use futures::{AsyncReadExt, TryStreamExt};
use geo_ip::utils::api_helper::ApiHelper;
use lambda_http::{http::StatusCode, service_fn, Error, IntoResponse, Request};
use serde_json::json;
use tokio_stream::StreamExt;
use maxminddb::geoip2;
use std::sync::{Arc, Mutex};
use std::{net::IpAddr, str::FromStr, time::Duration};
#[macro_use]
extern crate lazy_static;
lazy_static! {
static ref CACHED_COUNTRY_BUFFER: Arc<Mutex<Vec<u8>>> = Arc::new(Mutex::new(vec![]));
}
#[tokio::main]
async fn main() -> Result<(), Error> {
// init aws service
lambda_http::run(service_fn(|event: Request| execute(&s3_client, event))).await?;
Ok(())
}
pub async fn execute(client: &aws_sdk_s3::Client, event: Request) -> Result<impl IntoResponse, Error> {
let header_ip_address = event.headers().get("x-forwarded-for");
let bucket_name = std::env::var("BUCKET_NAME").expect("BUCKET_NAME must be set");
if let Some(header_ip_address) = header_ip_address {
let mut buf = Vec::new();
if CACHED_COUNTRY_BUFFER.lock().unwrap().is_empty() {
let mut stream = client
.get_object()
.bucket(bucket_name)
.key("GeoIP2-Country.mmdb")
.send()
.await?
.body
.map(|result| result.map_err(|e| std::io::Error::new(std::io::ErrorKind::Other, e)))
.into_async_read();
stream.read_to_end(&mut buf).await?;
CACHED_COUNTRY_BUFFER.lock().unwrap().append(&mut buf);
}
let reader =
maxminddb::Reader::from_source(CACHED_COUNTRY_BUFFER.lock().unwrap().clone()).unwrap();
let ip_address = IpAddr::from_str(header_ip_address.to_str().unwrap()).unwrap();
let country: geoip2::Country = reader.lookup(ip_address).unwrap();
if let Some(country) = country.country {
if let Some(iso_code) = country.iso_code {
let body = json!({ "countrycode": iso_code }).to_string();
return Ok(ApiHelper::response(
StatusCode::OK,
body,
"application/json".to_string(),
));
}
}
return Ok(ApiHelper::response(
StatusCode::FORBIDDEN,
json!({"message": "IP not recognized"}).to_string(),
"application/json".to_string(),
));
}
Ok(ApiHelper::response(
StatusCode::FORBIDDEN,
json!({"message": "IP is not present in the header request"}).to_string(),
"application/json".to_string(),
))
}
The code is straightforward:
- Download the binary file from Amazon S3
- Use the MaxMind DB crate to read the DB
- Search for the IP that I find in the header of the request
- Return the country code if found or forbidden
The exciting part is this:
lazy_static! {
static ref CACHED_COUNTRY_BUFFER: Arc<Mutex<Vec<u8>>> = Arc::new(Mutex::new(vec![]));
}
....
if CACHED_COUNTRY_BUFFER.lock().unwrap().is_empty() {
let mut stream = client
.get_object()
.bucket(bucket_name)
.key("GeoIP2-Country.mmdb")
.send()
.await?
.body
.map(|result| result.map_err(|e| std::io::Error::new(std::io::ErrorKind::Other, e)))
.into_async_read();
stream.read_to_end(&mut buf).await?;
CACHED_COUNTRY_BUFFER.lock().unwrap().append(&mut buf);
}
I read the file with a cold start request, and I cache the buffer in the lambda context for subsequent requests. When the Lambda service calls the function, the execution environment is created. As the lambda function can be invoked multiple times, the execution context is maintained for some time in anticipation of another Lambda function invocation. When that happens, it can "reuse" the context, and the best practice is to use it to initialize your classes, SDK clients and database connections outside. This saves execution time and cost for subsequent invocations (Warm start).
This operation will drop the execution of the Lambda at 1ms. You cannot get faster than this.
CSV Database
The CSV Database has more logic, and because you must query DynamoDB each time, it is much slower.
The CSV database has a network field that is not the IP address but the CIDR notation.
Reading from maxmind developer portal:
The network field of the database uses CIDR notation. Unfortunately MySQL doesn't offer any capabilities to work with data in that format, so we'll first have to convert the networks into something else that we can easily query later on. We chose to represent networks as a pair of IP addresses that are the first and last address in the network, respectively. We will convert this field so that both of these IP addresses will be represented as hexadecimal numbers.
I tried to follow the pattern, and so I ended up doing this:
Find the first and last IP address of the CIDR:
let cidr = cidr::IpCidr::from_str(&cidr).unwrap();
let first_address = cidr.first_address();
let last_address = cidr.last_address();
Convert them into numbers:
fn to_u64(self) -> u64 {
let ip_to_bytes = ip_to_bytes(self);
let u64_number = byte_to_u64(ip_to_bytes);
u64_number
}
fn ip_to_bytes(address: IpAddr) -> Vec<u8> {
match address {
IpAddr::V4(a) => a.octets().to_vec(),
IpAddr::V6(a) => a.octets().to_vec(),
}
}
fn byte_to_u64(ip: Vec<u8>) -> u64 {
let mut result: u64 = 0;
for octet in ip.iter() {
result = result * 1000 + *octet as u64;
}
result
}
Save into Amazon DynamoDB as:
https://www.ipaddressguide.com/cidr
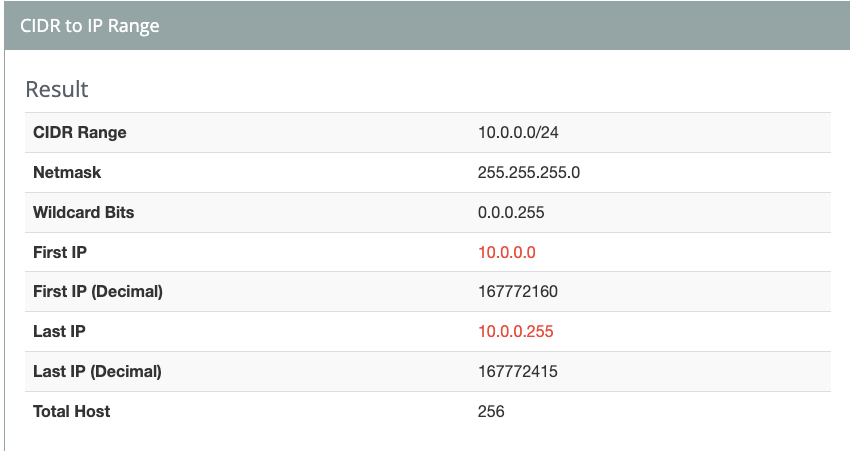
| PK | SK | MIN | MAX |
| 10 | 10.0.0.0/24 | 167772160 | 167772415 |
When you hit the endpoint API with the IP 10.0.0.1, for example:
- I take the first part of the IP - 10
- Convert the IP to a number 167772161
- Query against the PK 10
- Filter the results where 167772161 is between MIN and MAX
Conclusion
The binary version solution will scale much more than any payment service they could offer and be much cheaper.
I will consider the average duration of my test 50ms and not the min duration of 1ms.
If I refer to AWS Lambda Pricing
Monthly compute charges:
The monthly compute price is $0.0000000133 per GB-s, and the free tier provides 400,000 GB-s.
Total compute (seconds) = 3 million * 50ms = 150,000 seconds
Total compute (GB-s) = 150,000 * 1024MB/1024 MB = 150,000 GB-s
Total compute – Free tier compute = monthly billable compute GB- s
150,000 GB-s – 400,000 free tier GB-s = FREE
I think it is a good deal. All the above apply to whatever database I select because I need to change the interface with the client library to get the data that I require.
geoip2::Country
geoip2::City
geoip2::Isp
geoip2::ConnectionType
geoip2::AnonymousIp
and so on