
Serverless Latency: Understanding and Reducing the Delay

Serverless computing has become increasingly popular in recent years due to its ability to scale on demand and provide a pay-per-use model for computing resources.
At AWS re:Invent 2022 - Keynote with Dr. Werner Vogels, Werner gave a great speech and explained that the world is asynchronous and it is excellent, but if I step back and look at many applications, I see a lot of synchronous workloads.
I could convert to an asynchronous workload, but the fact is that the world is complex, and sometimes, for many reasons, you cannot/would switch to asynchronous.
During the past year, I went to conferences and user groups. Like everybody else, I follow the Serverless Gurus and have noticed that they all speak asynchronously in a serverless context.
When they show the hello world serverless example:

There is always, based on my personal opinion, some confusion on the fact that serverless is sold as:
Can scale from zero to thousands in instants
It is perfect for unpredictable and spiky traffic
While it is true, I found that the missing parts in those statements are:
If your workload is low
If spiky traffic is inside the Lambda quota
If you are not on the above cases, you will usually hear:
Convert all to asynchronous
Try to move to a region with a better quota
Let the Lambda services keep up returning errors to your users for X minutes
Do not use serverless
All the above makes sense on paper and in a perfect world, but sadly, it is only sometimes possible, and because I am stubborn as a mule, I decided to look a bit deeper and be more creative.
Latency is a complex subject, and it is composed of many factors.
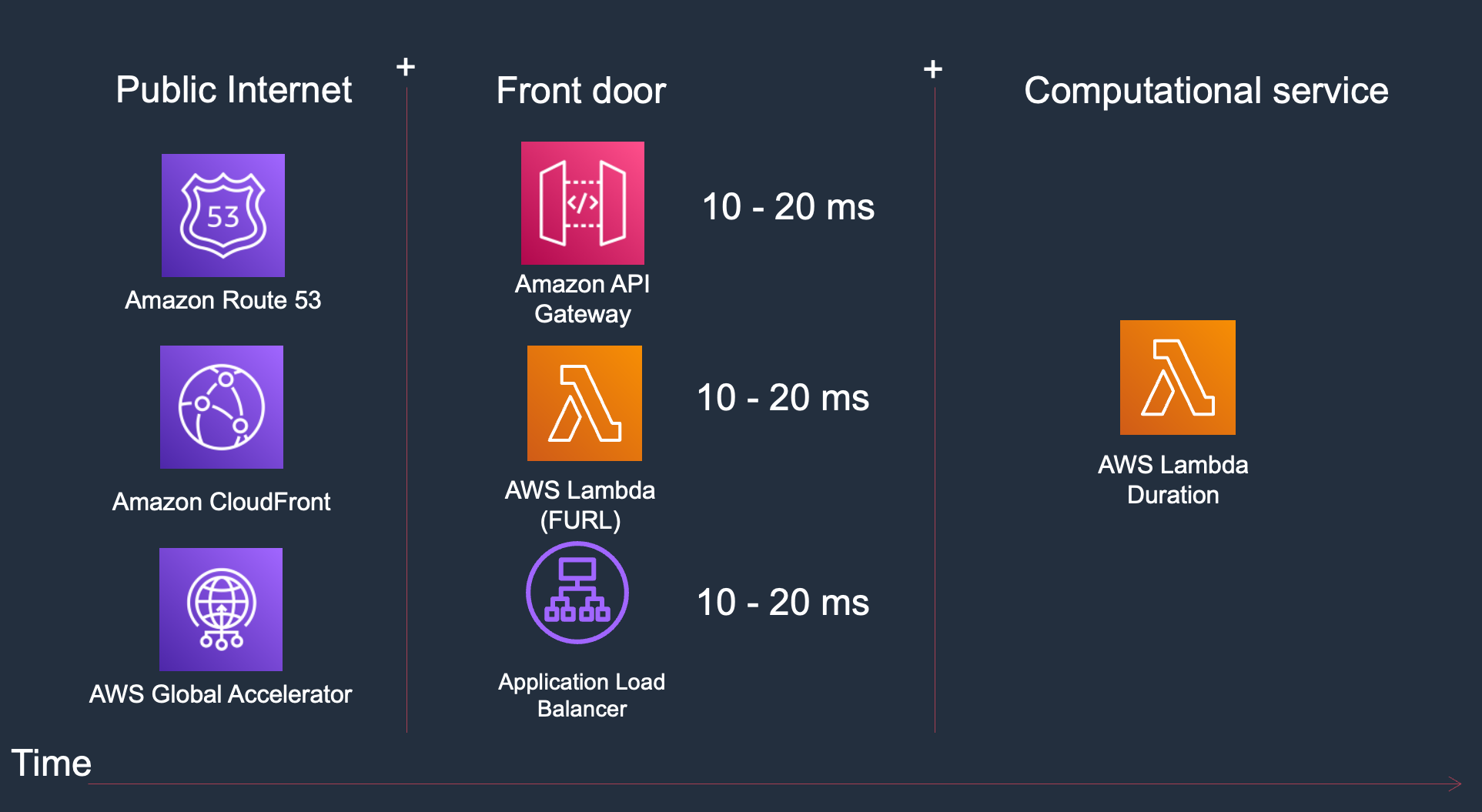
I have written in the past something The hidden serverless latency.
As you can see from the image above, I can optimize for the following:
How the user reaches my front door
Select the best front door
Optimise the AWS Lambda Duration
Of course, I can:
Caching at the client app
Caching at CloudFront
Caching at API Gateway
Caching in the Lambda function
Caching in front of the datastore
Caching can be complex, and it comes with its challenges. Moreover, I could use different services in the chain that do not provide any caching capability, and because of this, I am concentrating on AWS Lambda.
Legacy application
Imagine I have a Containerize application that receives an API input and inserts the payload into a database. Once the item is inserted, I must communicate this action to other services/departments and save this request for future analysis.
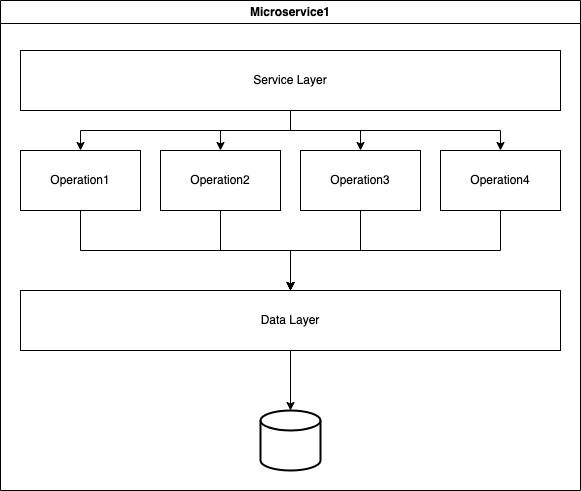
The Service Layer has the logic to run all the steps and send the correct information to each service/department.
This design has some obvious problems and becomes complex to update and maintain. Introducing new features, languages, frameworks, and technologies becomes very hard (it is just an example, and take it for what it is):
If I need to change one operation, I need to deploy all
If I need to add a new operation, I need to deploy all
If I need to change the flow inside the Service Layer, I need to test all carefully
If the data structure should change, I could have an incompatible issue
With the assumption that is what I got in the good and bad times, I now have new requirements (always an example):
Move to the cloud
Use native serverless services when it is possible
Improve the scalability of the application
Make the application more maintainable because currently, deploying takes more than 1h, and each time a bug takes days to fix.
Moving to the cloud
Assuming I am not an expert with Serverless, I will do my research and start replacing my legacy application with serverless native services. For reasons (that are not important to this article), I will end up to something like this:
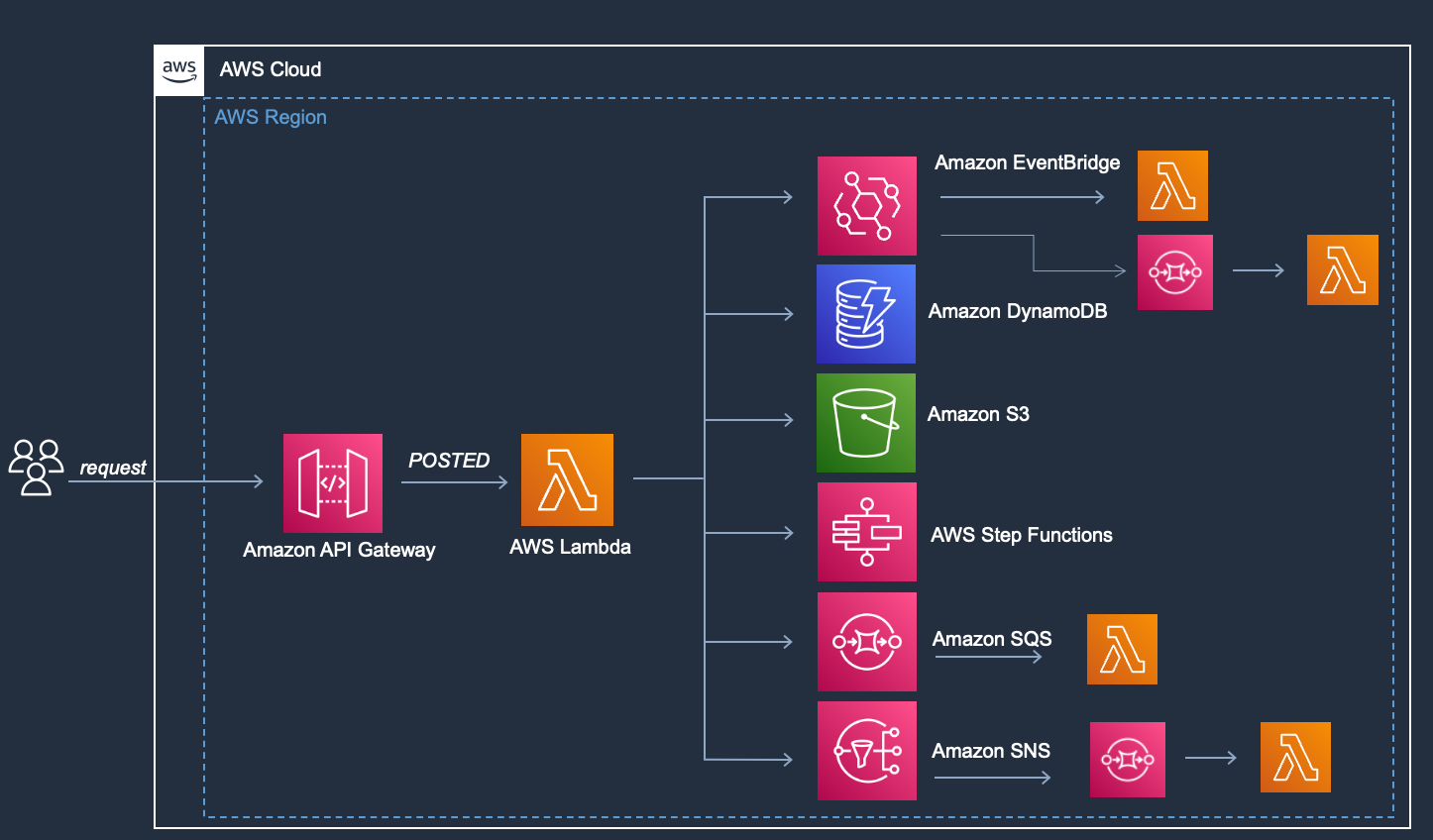
I have replaced Express.js with Amazon API gateway. The Service Layer code is now running inside AWS Lambda, where I orchestrate the connections with the old operations, and I have managed to move some of the procedures to different AWS Lambda functions.
At this point, I have satisfied all my new requirements, my boss is happy, and I deploy in production.
Does it scale?
It depends on what I want to achieve. If I develop this application without using any best practices, this application will run around 400ms with this setup:
node.js
Lambda at 1024 MB of memory
No parallelism
No usage of execution context
Burst quota 1000 Lambda
Lambda concurrency 1000
That will result in more or less 2.5K TPS. The integration between APIGW and Lambda is synchronous, and the quotas of the two services are different.
APIGW has 10K requests per second, while Lambda can serve only 1000 concurrent requests simultaneously (up to 3000 based on regions). So if it receives more than 1000 concurrent requests, some will be throttled until Lambda scales by 500 per minute. So the faster your Lambda is, the more load the application can support.
AWS Lambda is a serverless computing service offered by Amazon Web Services (AWS). As with any serverless computing service, latency can be an issue, especially for front-end-facing applications.
One potential drawback of AWS Lambda is the latency or the time it takes for the code to be executed in response to a request. Therefore, it is crucial To understand AWS Lambda scaling and throughput concepts.
Several factors can contribute to latency in serverless computing, including:
Cold start: When a Lambda function is invoked for the first time, there may be a delay because, at the same time, the necessary resources are provisioned, the code is initialised etc. Cold starts can add significant latency. But the Cold start is a small percentage in applications with a constant load but still can influence scalability
Network latency: The distance between the request and the front door of our application
Integration latency: Refers to the time it takes for serverless services to communicate with each other and for a Lambda function to communicate with other services through the aws-sdk API. Integration latency can be caused by various factors, including internal AWS network delays, the time it takes to establish a connection, and the time it takes to send and receive data.
Memory allocation: The amount of memory allocated to a Lambda function can also affect its latency. If a function lacks resources, it may take longer to execute.
This is what I consider monolith/fat Lambda. A "fat lambda" is a term used to describe a Lambda function that includes a large amount of code or dependencies, and it can be more resource-intensive to execute and may have longer cold start times.
From the image, I can see one AWS Lambda function does too many things:
Emit events using different services
Insert the request into DynamoDB
Save the request into S3
Run a Step Function flow
Several strategies can be used to minimise integration latency in a Lambda context, including:
Caching data: Caching data locally or in a cache service can reduce the time it takes to retrieve data from a remote resource, mainly if the information is accessed frequently.
Using asynchronous communication: Asynchronous communication, such as message queues or event-driven architectures, can help decouple functions from resources and reduce the time it takes to execute.
Minimising the size and complexity of code and dependencies: By keeping code and dependencies as small and straightforward as possible, you can reduce the time it takes for functions to initialise, which can help to reduce cold start latency.
Using compute-optimised instances: AWS Lambda provides arm64 and x86 architecture types, and by selecting the right architecture type for your functions, you can reduce latency.
Parallelism over Sequential processing: Using parallelism in lambda functions can help to improve performance by allowing the function to execute multiple tasks concurrently. This can be particularly useful for workloads that can be easily divided into independent tasks that can be processed in parallel.
Use Lambda Execution Context: As the Lambda function can be invoked numerous times, we can use the execution context to initialise database connection, HTTP clients, SDK clients etc. In this way, we do the initialisation only once instead of each time for each invocation.
Use a faster runtime: Rust is the fastest runtime that you can use. In addition, thanks to the single responsibility function concept, the complexity of the code is reduced, making Rust syntax the same as other common languages with significant benefits in Lambda Duration and Costs.
Following the best practice, I can reach the Single Responsibility Lambda and, ideally, an EDA scenario. A "Single Responsibility Lambda" is a function with a small amount of code and minimal dependencies, and it is generally faster and more efficient to execute. Moving in this direction, I can redesign the application into an Event-driven architecture where the first Lambda will fan out the event to downstream Lambda functions rather than running a predetermined sequence of steps.
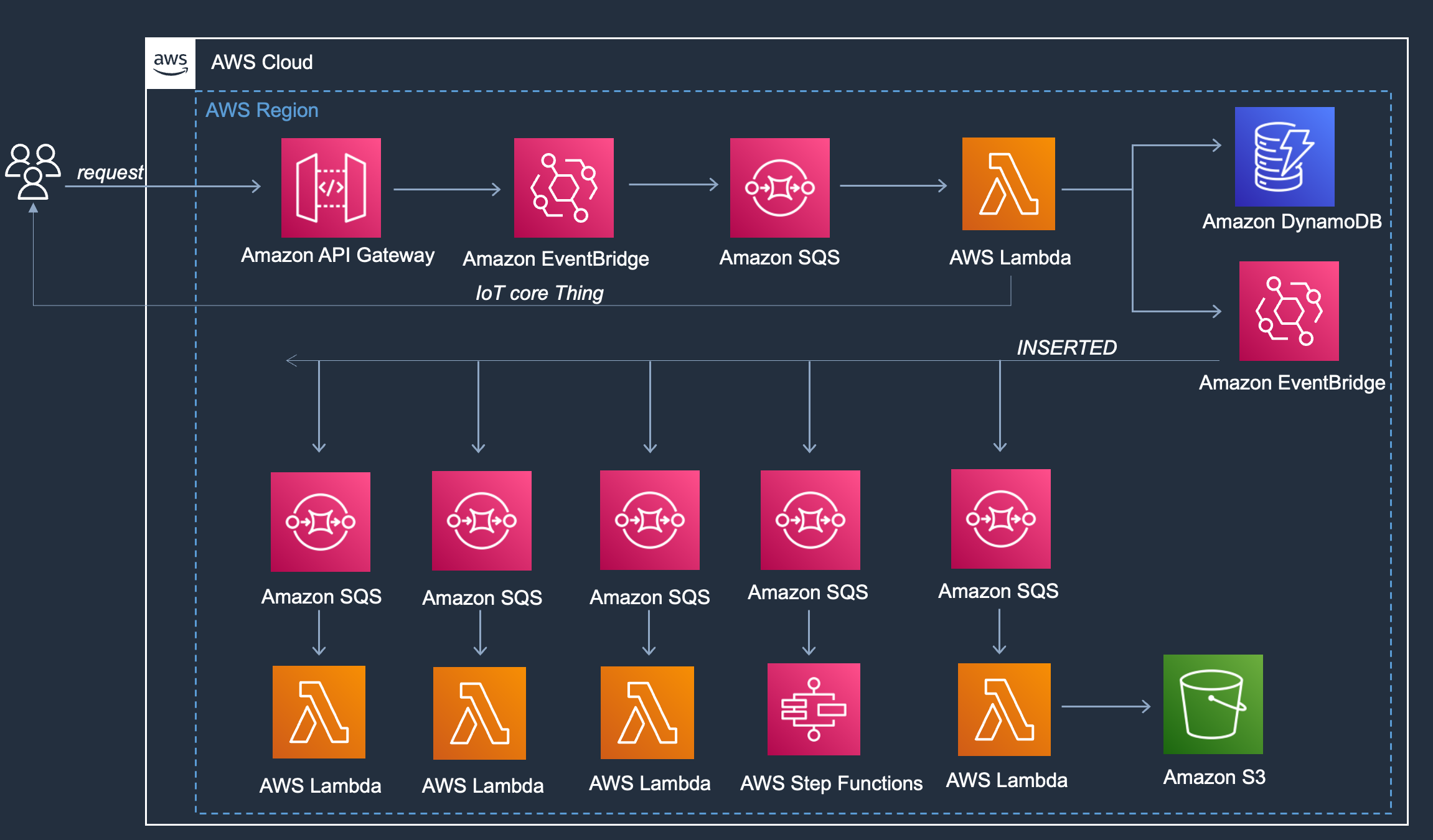
I have decoupled my application with this new design without touching the business logic. The application still receives an API input and inserts the payload into a database. Once the item is inserted, I fan out this action to other services/departments and save this request for future analysis.
With this design, I moved to an Asynchronous application.
I can receive a total of 10K requests per second from the APIGW or even more (which can be raised upon request) without worrying about throttling because the Lambda function consumes the messages from SQS, where I can control the speed of processing through a combination of two characteristics:
BatchSize: which is the number of messages received by each invocation
Maximum Concurrency: maximum concurrency allows you to control Lambda function. You set the maximum concurrency on the event source mapping, not on the Lambda function
In asynchronous workflows, it's impossible to pass the result of the function back to the origin because the caller acknowledges that the message has been accepted. However, there are multiple mechanisms for returning the result to the caller:
Build some custom logic and let the client do another call to check the status
I have found the most scalable is to use [IoT Core from a Lambda] (https://serverlessland.com/patterns/lambda-iot-sam).
Conclusion
Latency can be a potential issue with serverless applications, but some steps can be taken to minimise it. By following these best practices, you can help reduce latency in your AWS Lambda environment and ensure that your functions can execute quickly and efficiently. In addition, doing so will significantly influence your application's scalability (I wrote something in the past about Serverless scalability Serverless scale-ish), with an enormous gain in scalability.
What if I tell you that each best practices have a more or less 15% increase relation in scalability?
Even if I apply all the above and manage to:
Increased the scalability of my application
Moved to an asynchronous application
Used IoT Core to send a response to the user
I still have a minor issue with the response time and size to the user that will be slower and smaller than a Synchronous application.
End of the day, it is all about the tradeoff.