
Serverless scale-ish

This blog post will share my experience with serverless scalability and precisely for unpredictable spike scenarios. I will try to respond to the question:
Can we use Amazon API Gateway and AWS Lambda out of the box to reach the 10,000 RPS?
Before I answer this question, I tested the scenario with three runtimes:
Rust
GO
Node
The Lambda load a file from S3 and cache it in the execution context, and it returns a response synchronously to the APIGW.
Service Quotas
The general rule of thumb is to be aware of the limits of the services, and Amazon API Gateway has 10,000 requests per second (RPS) with an additional burst capacity provided by the token bucket algorithm, using a maximum bucket capacity of 5,000 requests. Lambda has concurrent execution of 1,000 but can be increased to tens of thousands.
Propaganda
Serverless is almost infinitive scalable, and it is perfect for unpredictable traffic.
My requirement
I want to expose an API endpoint to the public where the Lambda function will execute some compute and respond.
The traffic is unpredictable, and it could be no traffic or very few requests or thousands in seconds. So there is no clear pattern.
The request is not cacheable.
Options available
Considering that I am on purpose trying to find the limit, I would like to highlight that options that I could use in real scenarios are:
Cache
Multi-region
Provisioned concurrency
Cache
The main benefit of caching in Serverless applications is increased speed, reducing costs in some instances.
Caching at the edge with CloudFront is very cost-efficient as it cuts out most of the calls to API Gateway and Lambda, and so improve the end-to-end latency.
If CloudFront is not a good fit, I could use the API Gateway caching by selecting the cluster size and having more control on cache key, but because behind the scene is an ElasticCache cluster, the cost will go up, and I will also pay if I don't use it.
Of course, there is some caching using the Lambda execution context, and this will help to bring the duration down to a few milliseconds.
Finally, the last point of a cache is a database level like DAX or ElasticCache.
A good read about cache strategies can be found here.
Multi-region
Multi-region could help spread the load, but what if your load is just from one country?
The Geo options are not an option
Latency will always hit the same country
Weighted could help, but the percentage of people that will hit the secondary endpoint will get more latency on their requests without considering issues with the data compliance
Failover is not helpful in this case
Perhaps an option that could be possible is a multi-account setup and spread the load with the Weighted policy (I did not try).
Provisioned concurrency
Provisioned concurrency is sold to solve the cold start and respond quickly to many requests. What if the traffic is unpredictable? In this case, provisioned concurrency is not a fit. With provisioned concurrency, I currently have two options:
Always on
Scheduled time
Always on is costly and does not fit the unpredictable case. The scheduled time is not a fit, and by the way, it takes up to 3 minutes before the Lambda functions are all warm. If we could activate it on demand with some CloudWatch alarm, like when the concurrency reaches some level, it could be used, but it will be problematic because of the spinning time.
More info here.
Does it scales?
These quotas that we are getting out of the box are acceptable for the normal workload that does not require a high level of RPS or where the requests are coming in slowly, and here is where my challenge starts.
I have found not much scaling in a similar scenario, and once you check all the options described above, it is pretty challenging.
The challenge turned out to be the famous Burst concurrency quotas
3000 – US West (Oregon), US East (N. Virginia), Europe (Ireland)
1000 – Asia Pacific (Tokyo), Europe (Frankfurt), US East (Ohio)
500 – Other Regions
Burst concurrency is simpler words are the instances that you can use in an instant.
I cannot reach 10,000 RPS for spiky workloads outside of the regions US West (Oregon), US East (N. Virginia), Europe (Ireland) and there is no way unless AWS will adapt the burst with the current limits and so the first thing is to increase the Lambda concurrency quota. Even if they set 10K Lambda concurrency, the issue is still the burst concurrency because it will block any peak traffic. However, the concurrent Lambda functions will drastically decrease when the peak is handled inside the burst. This means that you will not solve the problem of handling peak traffic just by increasing the Lambda concurrency.
The test plan that I used is like this:
(rampUsers(3000) during (60 seconds)).
throttle(jumpToRps(54), holdFor(5 minute),
jumpToRps(102), holdFor(5 minute),
jumpToRps(498), holdFor(5 minute),
jumpToRps(1500), holdFor(5 minute),
jumpToRps(3000), holdFor(5 minute),
jumpToRps(4998), holdFor(5 minute),
jumpToRps(10002), holdFor(5 minute))
As you can see, I stay just above the 10002 RPS
eu-central-1
I have tried many combinations and found the issues only when moving from 5K RPS to 10K RPS.
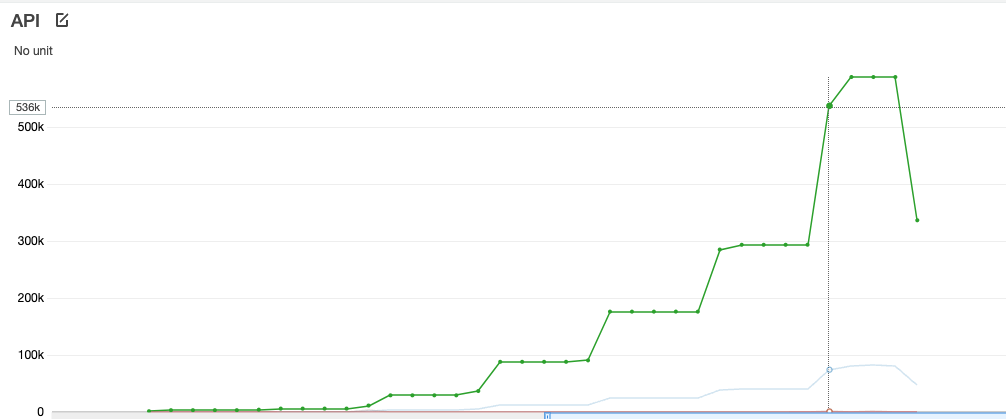
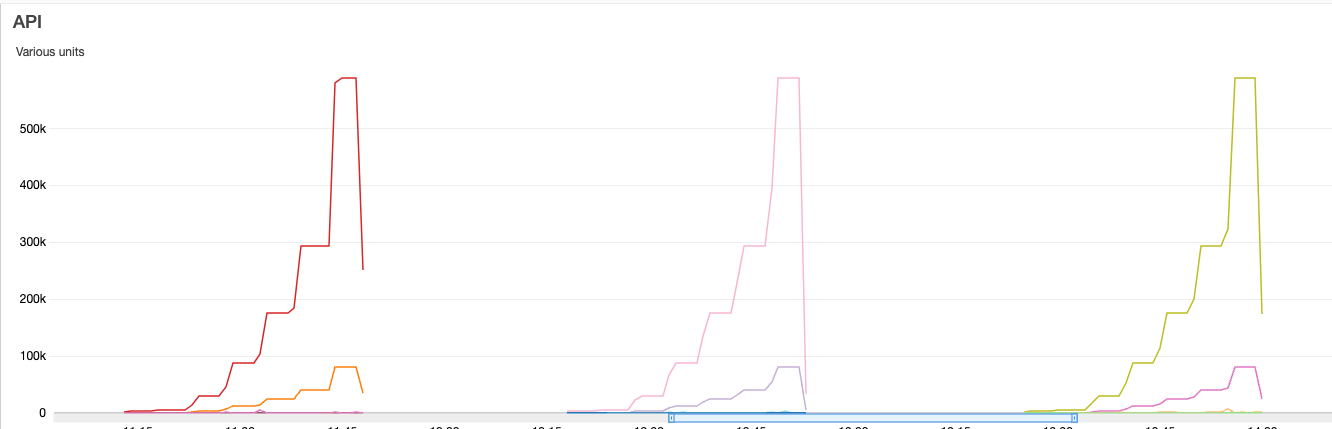
At the point highlighted on the graph above, this is what is going on at the Lambda function level:
It moves from 150 concurrent Lambda functions to over 1000 simultaneous Lambda functions, where the burst is reached, resulting in a 503 status code in the APIGW.
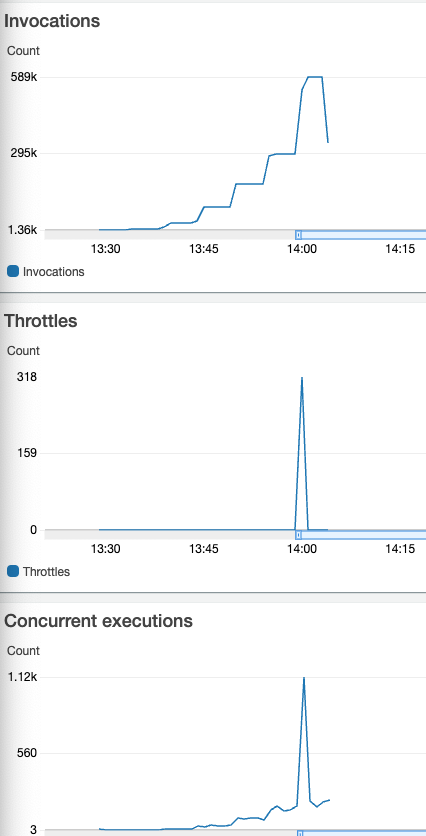
If I stay under the 10000 RPS, it is all working as it shows on this graph:
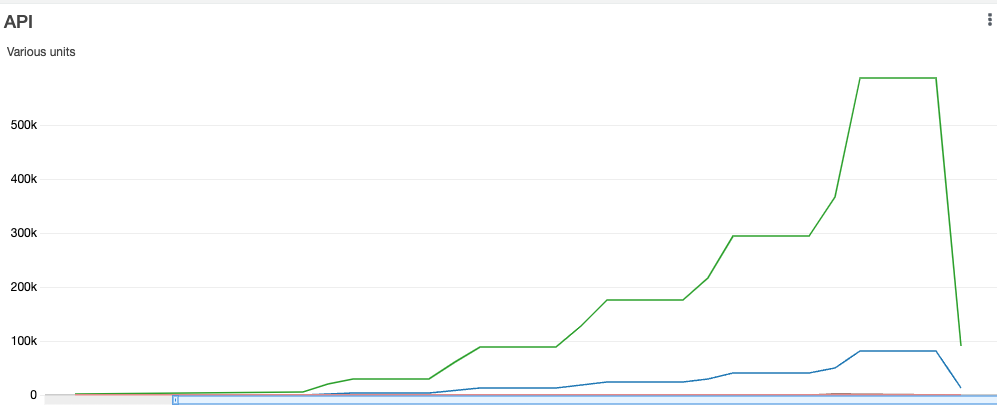
and this is the Lambda view:
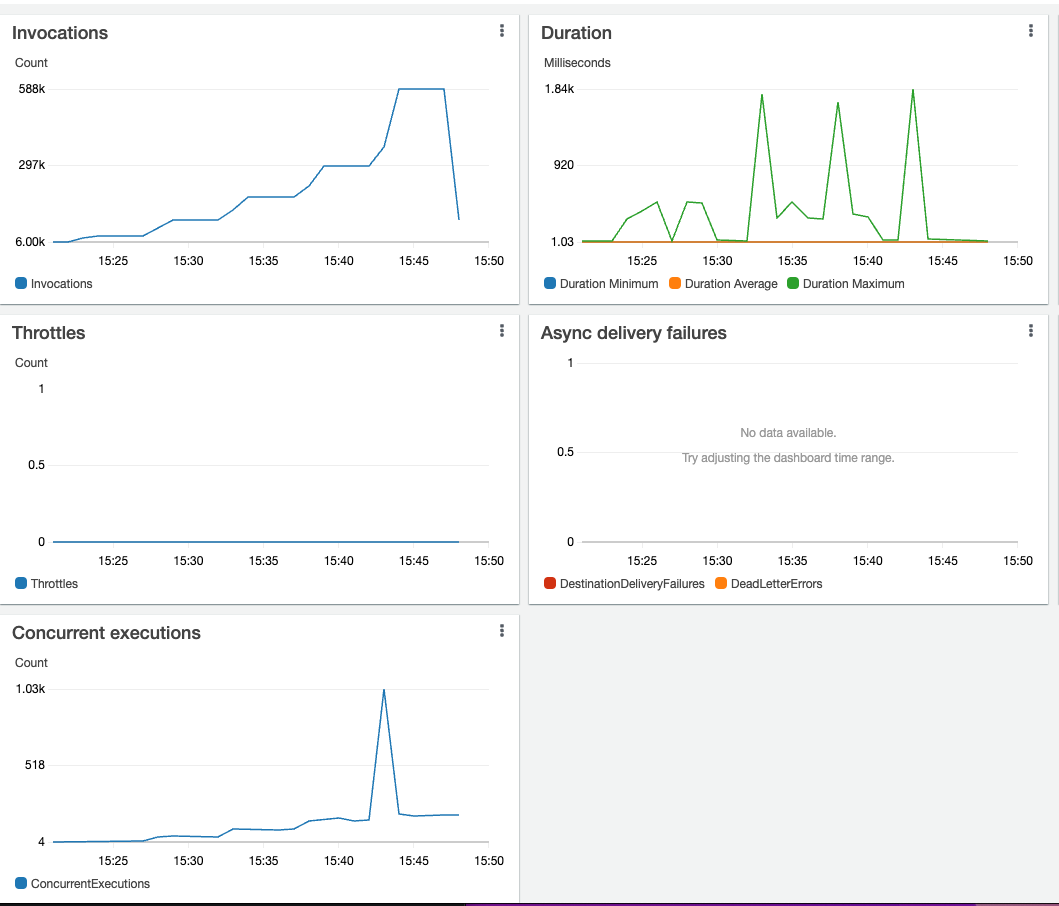
When the peak of the concurrent Lambda function happens, the latency moves from a few milliseconds to seconds.
eu-west-1
Knowing that the issue is the burst concurrency, I wanted to try in Ireland, where the burst limit is three times higher than Germany and the results, as expected, are all positive:
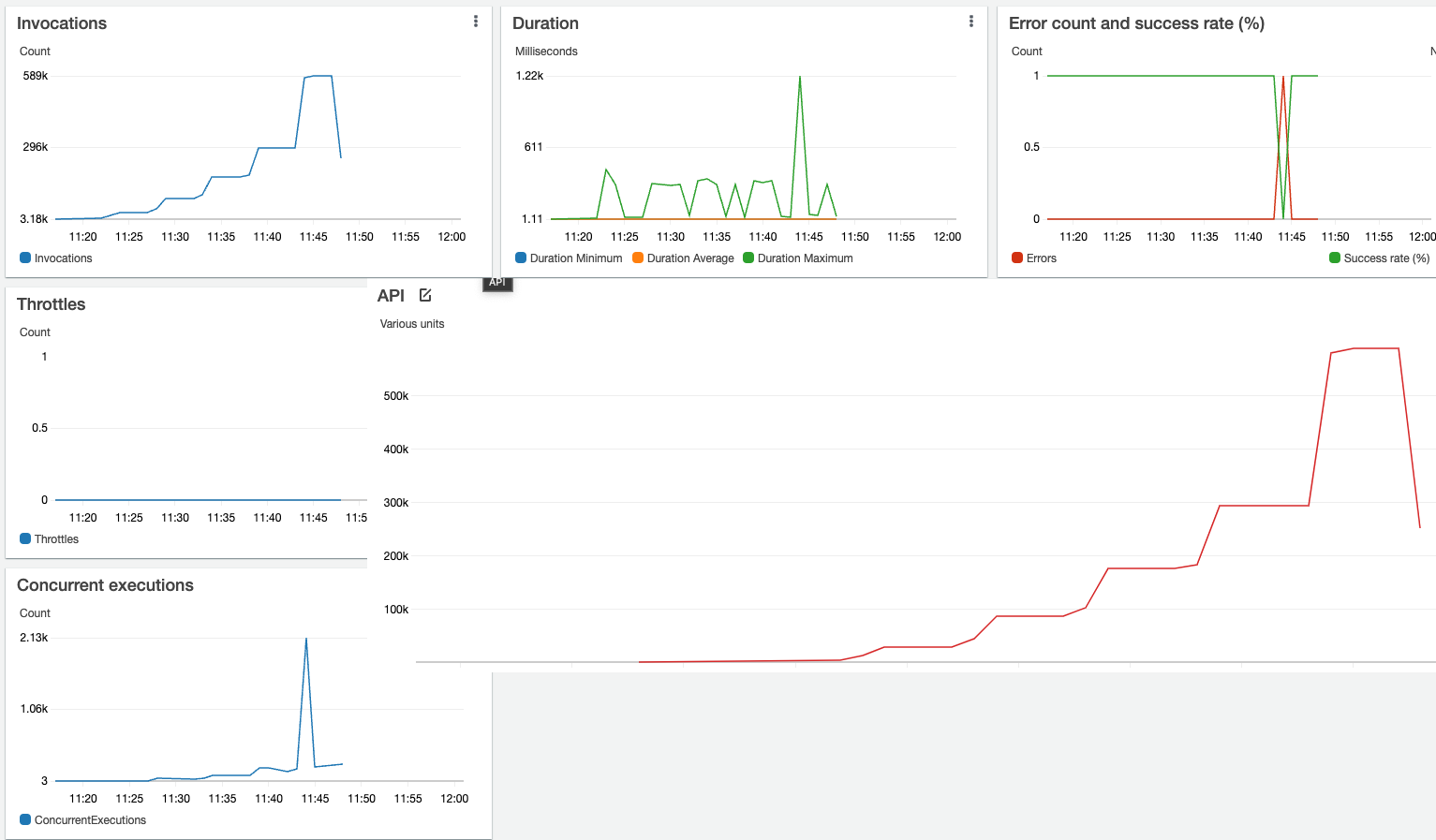
There is always that strange jump from a few hundred concurrent Lambda functions to thousands of concurrent Lambda functions.
I have no idea why this is happening, considering that there are already many warm and the current latency at this stage is just a few milliseconds.
Until now, I have run one runtime per time, and I have noticed that they are pretty much similar, especially Rust and GO. Sometimes Rust is faster, and sometimes GO is faster. I think it depends a lot on AWS network latency at that moment.
For example:
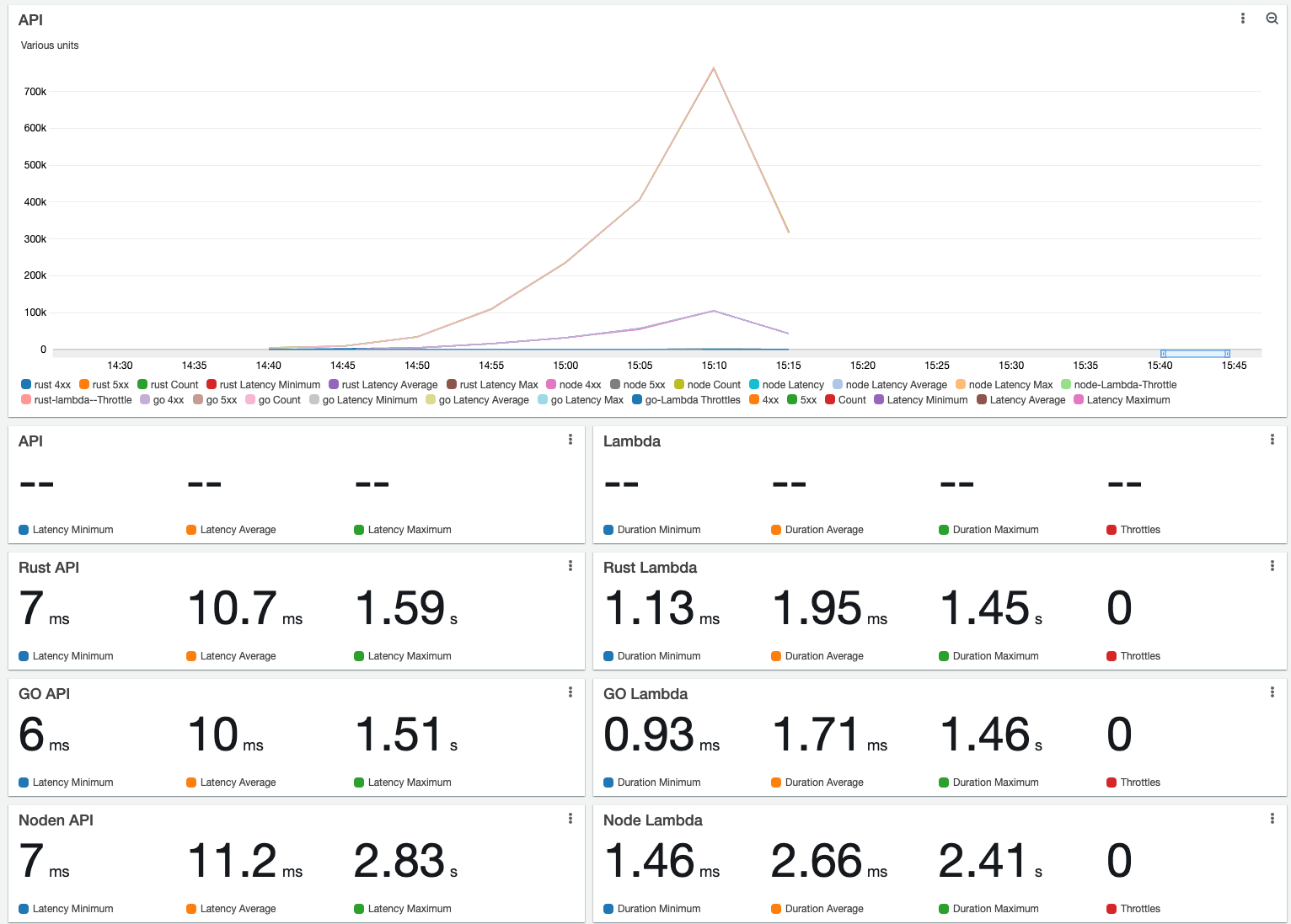
Another run:
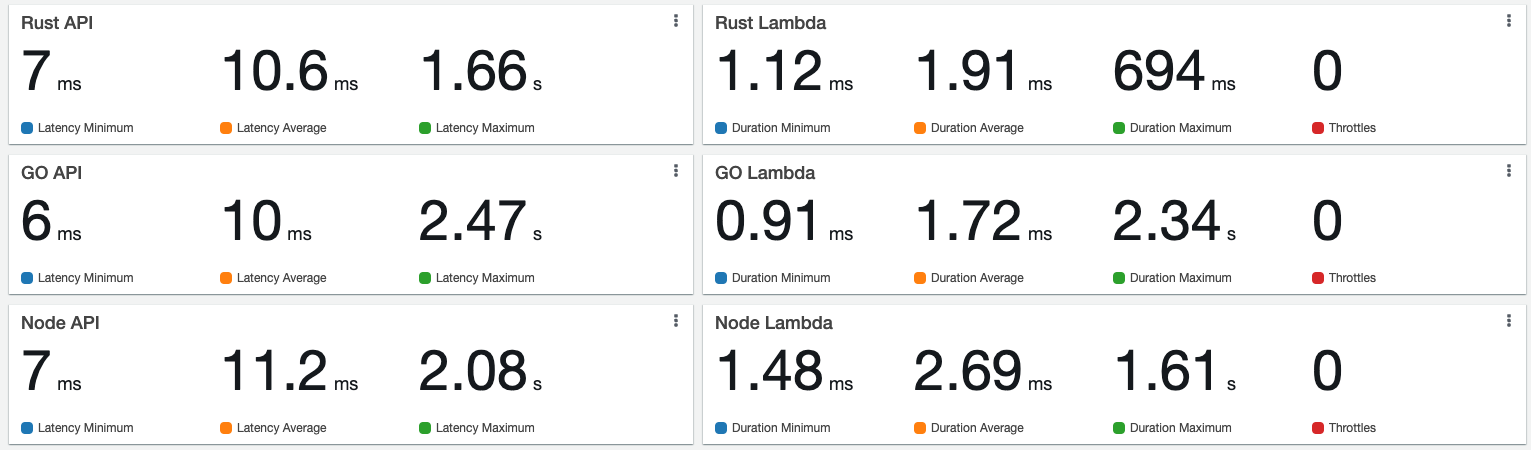
Cold start vs Warm start:
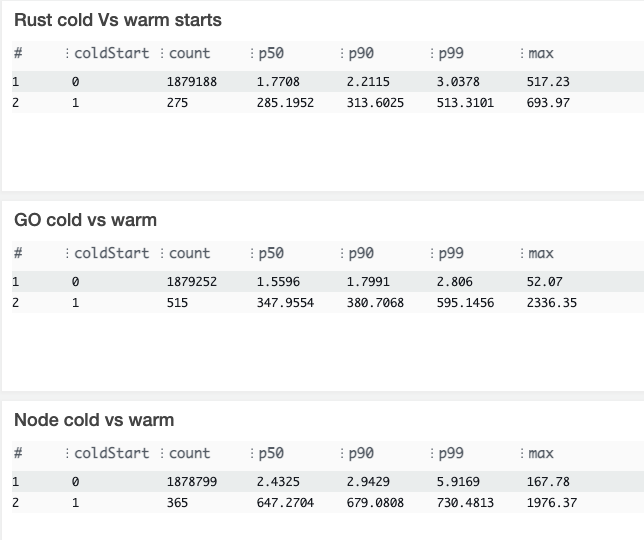
Lambda insights:

Conclusion
Serverless can scale, but the famous unpredictable traffic is also a problem for serverless. So outside of US West (Oregon), US East (N. Virginia), Europe (Ireland), I would say that is pretty impossible unless the workload is flatter and not hit such a spike.
Suppose you have sudden peaks, as I have shown on the graph. In that case, you can hit the burst concurrency, and perhaps a simple retry policy on the client-side can be the solution. Still, if you do not apply all the tricks like cache, retries etc., serverless does not scale for unpredictable high traffic as promised. Regardless of the tricks and optimisations, you will hit the burst concurrency at some point, resulting in many errors until there are enough instances to serve the current load.
I must say that is obvious because, in the end, there are machines under the serverless magic, and the same load will crash any cluster unless you will setup more or less 15 machines to handle a similar test. Therefore, I do not want even to start the ToC discussion.
To answer the original question:
Can we use Amazon API Gateway and AWS Lambda out of the box to reach the 10,000 RPS?
The short answer is it depends on the workload. Outside of US West (Oregon), US East (N. Virginia), Europe (Ireland), not spiky traffic could be handled while spiky traffic like this blog post example only in the regions where the burst capacity is set to 3000.
I get the points to move to async communication or using some caching, but I am sure there is a use case where you need to hit the endpoint, and a calculation that is not cachable must be done at scale.
How do you solve this issue with the three amigos:
APIGW - adjustable
Lambda - adjustable
Burst (not adjustable)
I hope that the burst quotas will be soon the same in all the regions and see some AWS experts taking this case and showing a possible solution.
Nevertheless, it is essential to test any application to discover those issues and deploy countermeasures.