
The hidden serverless latency

I want to share something you don't hear much about, which bothered me a bit. Talking around it seems so few are aware or always forget about it, making a perfect opportunity to increase awareness and demand better performances.
I want to state the obvious that serverless services are not magic. AWS needs to spin up the instances we are using under the hood and create a connection between the services, called integration latency.
This post is about the integration latency and precisely on a classic microservice architecture:
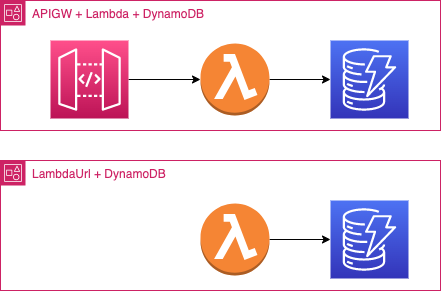
I consider two possible ways to get some data from the data source, in this case, DynamoDB. However, I am not considering the direct integration of APIGW to DynamoDB on purpose because, sadly, I always have business logic to apply and prefer Lambda over VTL code.
With this clarified, let me make a small latency comparison for the 3 options:
| |APIGW REST | APIGW HTTP | FURL | |-|-|-|-|-| |pricing|$3.5 per 1M req.|$1 per 1M req.|free| |latency| 10-20 ms| 10-20 ms|10-20 ms|
Since APIGW HTTP seems not to get new features (a walking dead), I tend to use only the REST type all the time, but you can see a comparison here. While for differences between AWS Lambda Function URL (FURL) & Amazon API Gateway, have a look here.
Assumptions
The integration latency between 10-20 ms is often considered average, which also applies to DynamoDB operations. Of course, integration latency could have a vast fluctuation, especially with DynamoDB. It is also true that they can have a little integration latency of a few ms.
My problem
I have moved a service out of an ECS cluster and compared the performances. Sadly, serverless was slower. This is because the ECS cluster used Redis before the data source.
Architecturally speaking, they are not the same, but I have to answer the question of why moving to serverless if overall I get worse performance. Of course, costs, maintainability, and scalability are part of the answers, but what if they are not a problem in the current status quo? So performances become a problem.
I consider APIGW integration latency between 10-20 ms for this article. This means that if my Lambda function runs in 10ms, including the DynamoDB operation, I should add on top at least extra 10ms for a total response of 20ms. Not bad!!!
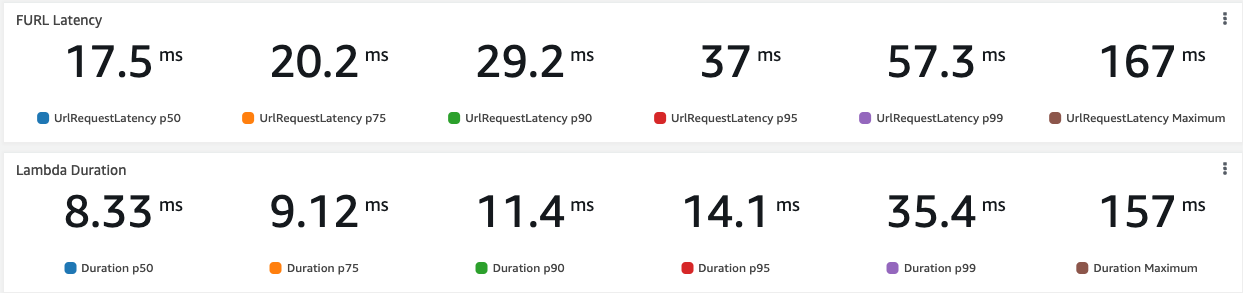
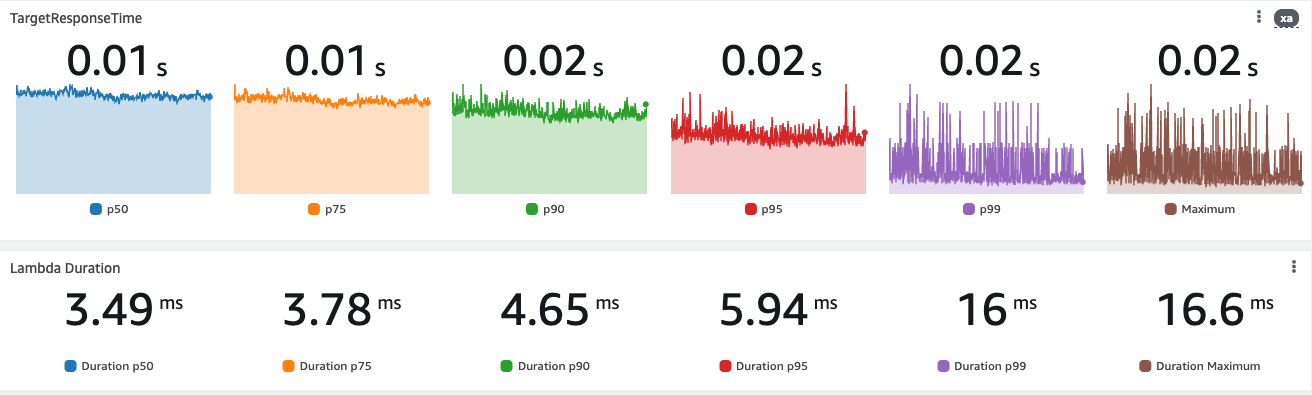
The difference between the Lambda Duration and the Integration Latency (as stated above, there is not much difference between APIGW types and Lambda Function URL) is visible from this test:
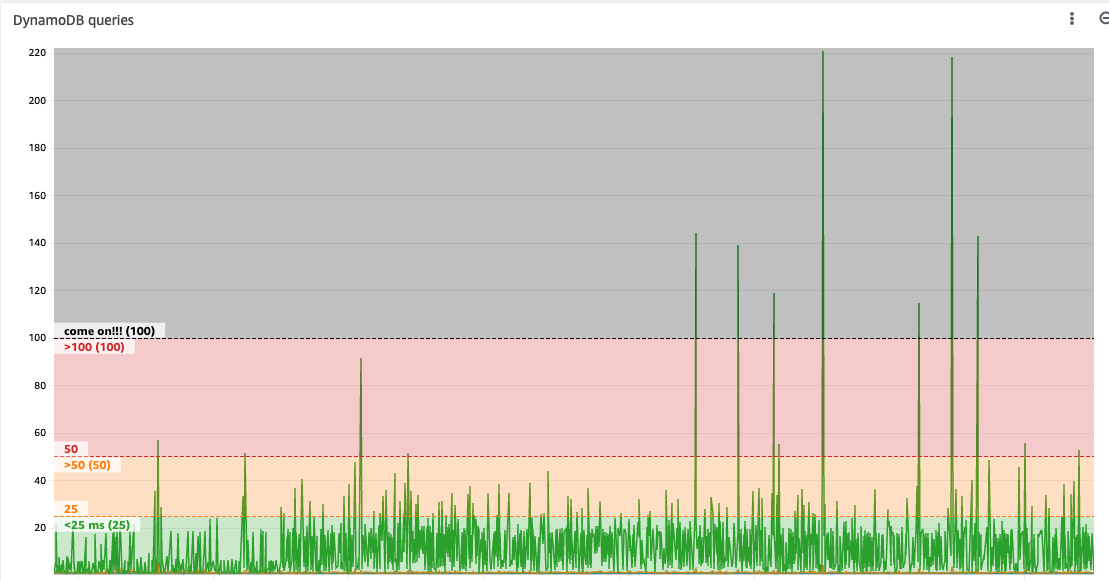
For DynamoDB, the latency fluctuates, and as you can see from the graph, it could slow down the Lambda if I do not use a timeout policy.
I do not accept that Serverless cannot be used for latency-aware applications. I am not looking at the 1ms result here. Regardless, I do not want AWS integration latency to become the cause of why my service is slow or, worse, to be advised to move to Cluster architecture with all the other possible challenges (scalability, costs and so on).
What can I do?
AWS operate all their systems globally, and it is normal to experience latency spikes. These spikes can occur for many reasons, and regardless of the root cause, an application that interacts with the AWS service should be tuned to follow a retry strategy that helps avoid latency spikes. More about Retry behaviour.
What I usually do for DynamoDB is to set the following settings:
2 retries
backoff interval 15ms (50 should be the default one)
single attempt operation 30ms
And considering a similar implementation:
let exp_backoff = 15ms * 2.pow(current_attempts - 1)
let jitter = random between(1 and exp_backoff);
let final_backoff = exp_backoff + jitter;
I can calculate the worst-case scenario before timing out the DynamoDB operation with all the retries.
For the front door of my service, I have a third option:
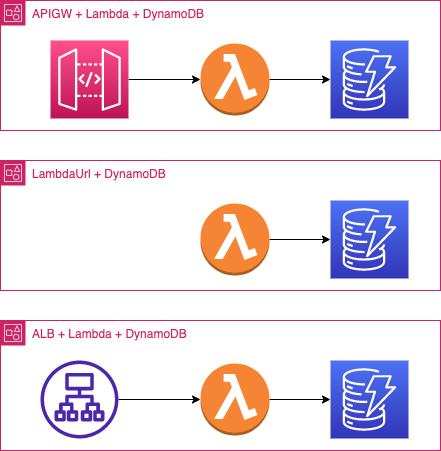
Considering the ALB, the comparison changes into:
| APIGW REST | APIGW HTTP | FURL | ALB | |
| pricing | $3.5 per 1M req. | $1 per 1M req. | free | $0.027 per hour |
| latency | 10-20 ms | 10-20 ms | 10-20 ms | avg 0.0.x ms |
For more info about pricing:
The Application load balancer integration with Lambda is coming at an extra cost, but I have now a stable latency of a few ms in front of my Lambda function.
As with everything, each use case could be different, and security, costs, and so on must be considered before using one service over another. Nevertheless, my take is that many do not consider the ALB because it is often not even considered or mentioned by anyone in the Serverless world. I refuse the "Serverless is not good for latency aware applications" sentence.
Replacing APIGW or Lambda Function URL with ALB and configuring an aggressive timeout policy to DynamoDB, I reached the point where my serverless service performance is as good (as) or better than the old service architecture (ALB + ECS + Redis + DataSource).
Conclusion
I am not asking magic here. Instead, I am asking AWS Serverless teams to move forward and give us the next generation of serverless applications.
Amazon DynamoDB Accelerator (DAX) is excellent. Still, since it requires running a Lambda inside a VPC, there are other challenges, especially if the application needs to handle spikes.
DynamoDB latency fluctuates, and without a good strategy of timeouts and retries, it will increase the Lambda Duration to seconds (a small % of invocations).
I do not know what is the solution here. However, I want to avoid Serverless ending up like The 17 Ways to Run Containers on AWS.
Currently, we have three ways REST, HTTP and Lambda Function URL, and each covers similar but different scenarios.
I would challenge the choice of having three services with why not try to improve the APIGW REST API (the oldest) by adding the new things of APIGW HTTP API and Lambda Function URL instead, and giving the customers ("customer obsession") a service with more potential and flexibility.
I wish an overall focus on the quality/performance of the current services to make Serverless the undiscussable Standard.