
The state of AWS Serverless Development
A builder reflection

In this post, I want to share my consideration and personal opinion of the state of AWS Serverless Developers.
AWS Serverless offering has evolved a lot over the years. I have been developing with AWS Lambda functions since 2016, and the progress and best practices have put me in positions to build scalable applications. Scalability is a big word, and we should put a number behind it. In my case, I can reach millions of requests per minute without moving a finger but just applying the practice that the AWS Serverless DA teams have been presenting for years.
Lambda alone is nothing, and in fact, the serverless offering started way back:
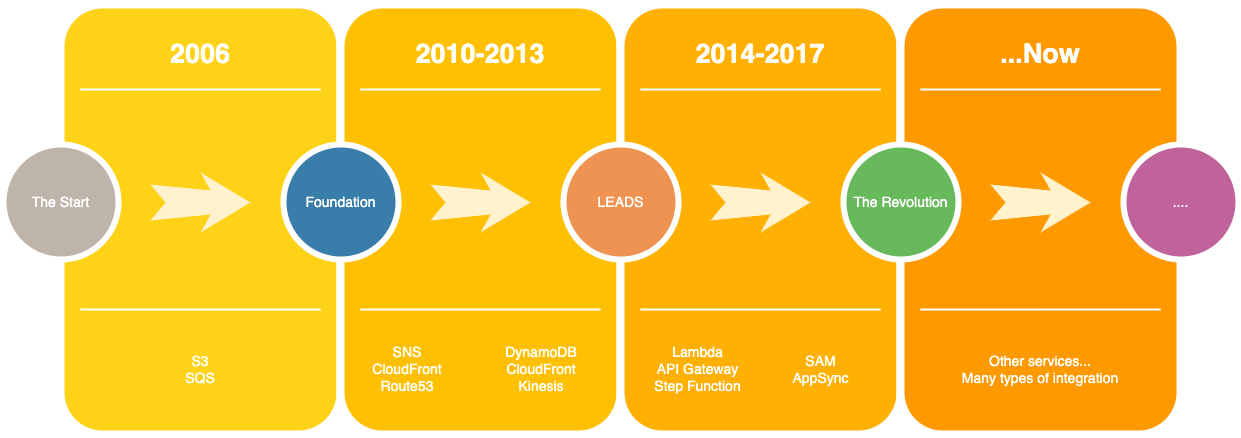
The current problem is that people jump on the Serverless train without understanding what it takes. Many would say that Serverless needs a different mind shift or that it is much harder to learn because you need to connect all the services. I have found all of this not valid for someone like me, whom I have been around for a while and experienced both worlds.
Before serverless to be a decent developer, you have to be aware of concepts like:
- Dependency injection
- Domain-Driven Design
- CQRS
- Event Sourcing
- Hexagonal architecture
- 3 layer architecture
- ORM
- Repository pattern
- Aspect-oriented programming (AOP)
- Automocker
- SOAP, WPF, REST
- EventBus, Messaging
- and many more...
On top of this, you need to package all and deploy on some server, and there you need to get specialised or pass the ball to the next team and hope for the best.
With serverless and the single responsibility, Lambda becomes something straightforward, and I don't need most of the concepts above because now the flow is simple:
- Handle the event in the input
- Do something, transform and so on
- Emit events
- Return
This does not mean you can jump on the Serverless train and expect magic.

If you want to be Serverless Developer, you must know the best practice of the provider you are using on top of the basics that are always valid in the industry.
I like to say that serverless development is like

I have many components with specific configurations, and I must connect them to create something fantastic. As a developer, I need to do my part because even if serverless automatically scales thanks to the built-in parallelisation and concurrency, my application will fail if I will not correctly connect the bricks. So while before, it was just "this is my application, please make it run in the cluster", now this will bite you back, and this is the reason for this article.
I believe there are 3 types of developers (very generic, the reality could be more complex):
- The one that does the job just for the paycheck
- The one that likes it but is lazy to learn and prefers to be comfortable his entire life
- The passionate
The first two always have an excuse like:
- I have no time
- I need training all time
- I disagree with the standards
- I know better
- Ah well, I want to do like this instead
- I do not need help
- I do not want to upgrade it
As generic the above can be, it is a fact that this kind of behaviour exists everywhere. So often, people start a new technology serverless or cluster or whatever without really trying causing more issues or worse, complaining that it was better to stay with whatever we have been doing for the last decade.
It is like saying the Ferrari is not better than FIAT because I have crashed.

The problem I constantly see when people start working with Serverless, specifically with Lambda, is that the average developer complains because Serverless is not as fast as the good old Cluster. At this point, I ask my 3 uncomfortable questions making myself the enemy number 1:
Almost all the time, I discover that people try to run a serverless function without many thoughts. When we are working with AWS Lambda, we should understand the Lambda lifecycle:
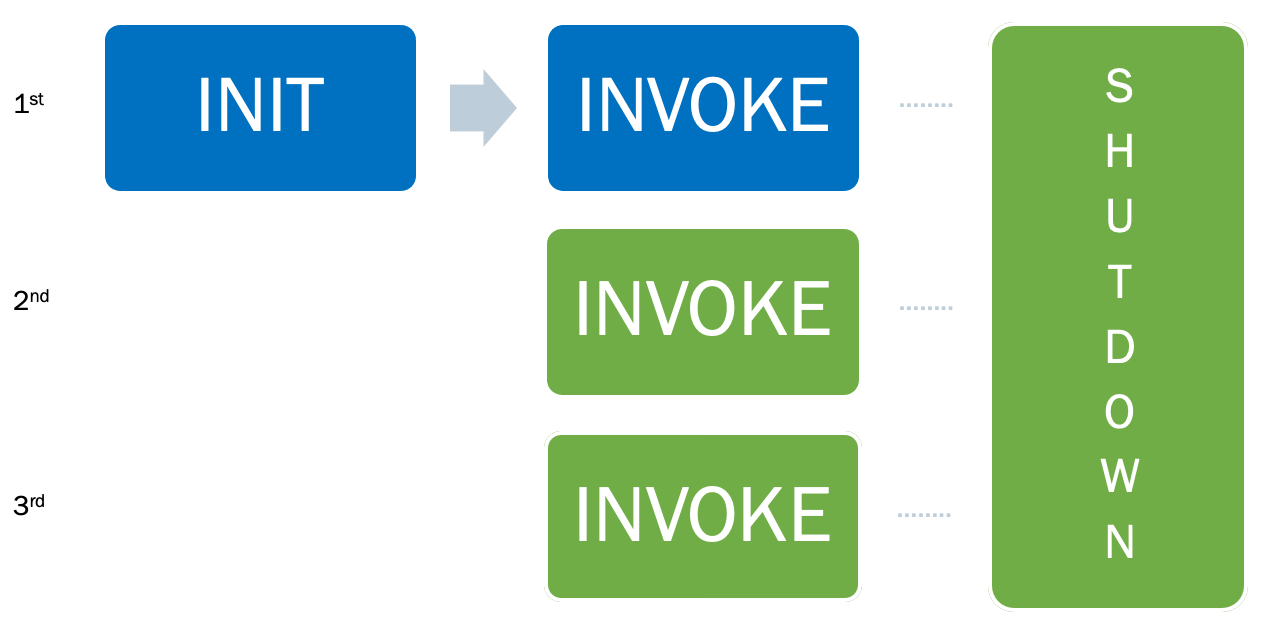
The Lambda lifecycle includes the following 3 phases :
INIT
- Start all extensions
- Bootstrap the runtime setting up the environment (memory, runtime and so on)
- Download the code,
- Runs the function's initialisation code (the code outside the handler)
INVOKE
- Invoke the handler
- After the function runs to completion
- Prepare to handle a new request
SHUTDOWN
- Alerts the extensions to let them stop cleanly
- Then, removes the environment
In short, when a request arrives and a Lambda is not already running, AWS needs to deploy the code and spin up a new container with all the configurations before the request can begin (INIT). Once the container is ready, it will execute the handler (INVOKE). After the first invocation, the container is ready to process a second request until no requests are coming in, and at this point, the Lambda service will freeze the container or shut it down.
With the lifecycle in mind, as a developer, I know that I can reduce latency and increase the throughput of my Lambda cold start and invocations doing my part.
Regardless of the runtime which my Lambda function is running is well known that I should follow best practices like:
- Deploy small packages
- Use Lambda Execution Context
- Avoid Fat Lambda
- Use parallelism when possible
- Use Arm64 architecture
- Find the optimal memory balance
I can guarantee you that most of the time, many if not all, are not followed.
Serverless development is in 2022 in a state that is almost the clear choice for nearly everything because we have reached a point where the ecosystem is mature (not perfect) and with many communities out there to follow like:
- Serverless DA
- Community Builders
- AWS Heros
- AWS Serverless specialist
It is pretty difficult to miss the basics, but somehow, we as the industry are still ignoring the best practice, and often I wonder how this is even possible (see the 3 types of devs above).
As you know, I like writing my Lambda functions in Rust. I started my career using .NET and moved to Node.js in 2016 when I migrated and never looked back. I struggled to move from a compiled language to an interpreted language, but at the time, it was the only choice and programing language apart, there was an obvious reason to use Node.
With time I got used to the different syntax and the baggage that comes with a language, and I moved towards the idea of being a polyglot developer (still working on it). Of course, there are advantages and disadvantages, as in everything, and I often admit I do not remember the correct syntax or mix it up. Still, I have found this skill, if you want to call it like this, to be helpful in serverless development. As my age/career progressed, I am no longer fun of a particular language and let me tell you why.
I had a problem on my hands - "Build an application that scale and keeps the cost down".
As some said, you cannot build a scalable and reliable application at a lower price. This is not totally true anymore because we are in a time where the AWS Lambda runtime can be written in any programming language.
Let me be clear: I am not advocating changing runtime and rewriting all the applications. There are many factors to consider, skills, company policies, mentality, managers and so on, but I believe that we have reached a phase of Serverless development where a runtime can make a difference.
In a world of single responsibility functions, the complexity is reduced to almost zero, and we are left just with the syntax of a programming language that should not be a problem (copy and paste here and there or asking around) considering that we are software developers. Suppose a runtime does not support something or there is a bug. In that case, I can easily use the Lego mindset and write the Lambda function in a different runtime without being precluded exclusively to one runtime.
As all runtimes are not born equal, we know today that the slowest and most expensive runtimes are in order:
- Node and Python
- Java and .NET
- Golang and Rust
If we consider the following test:
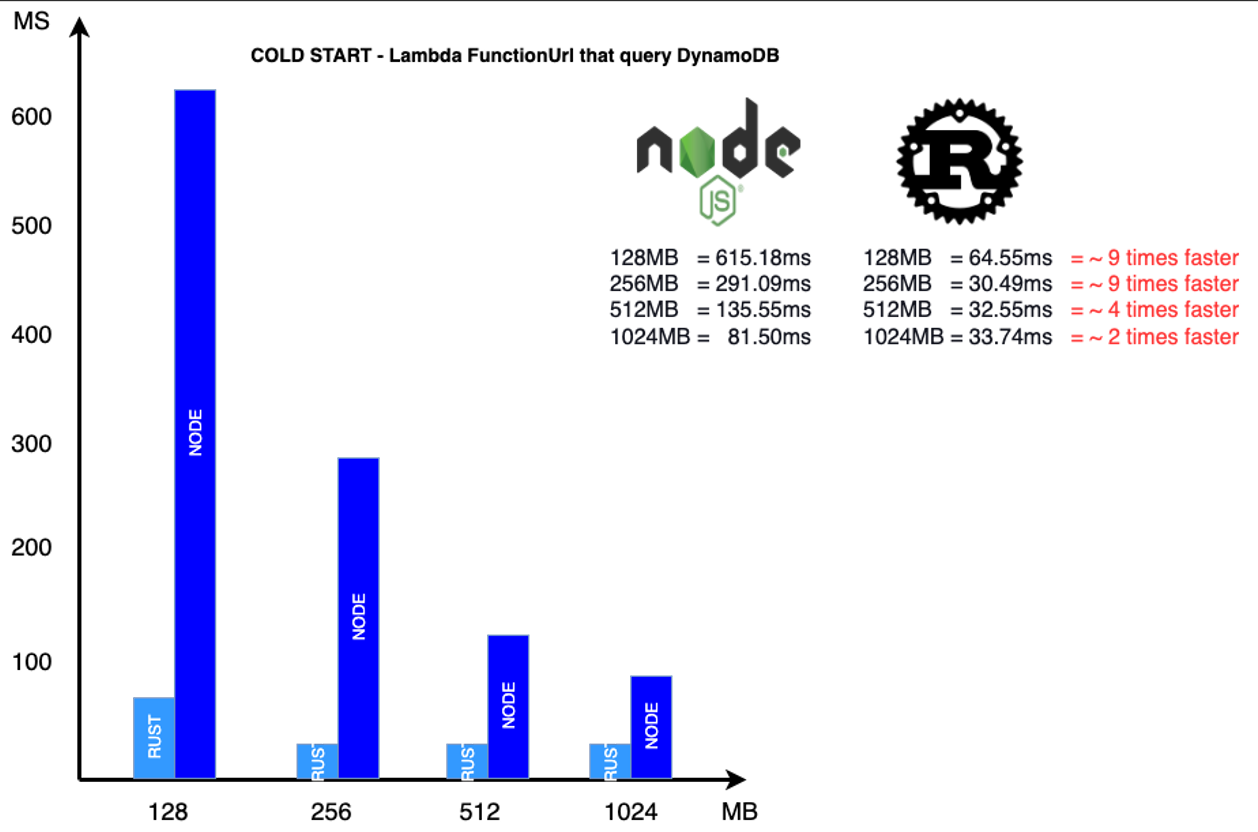
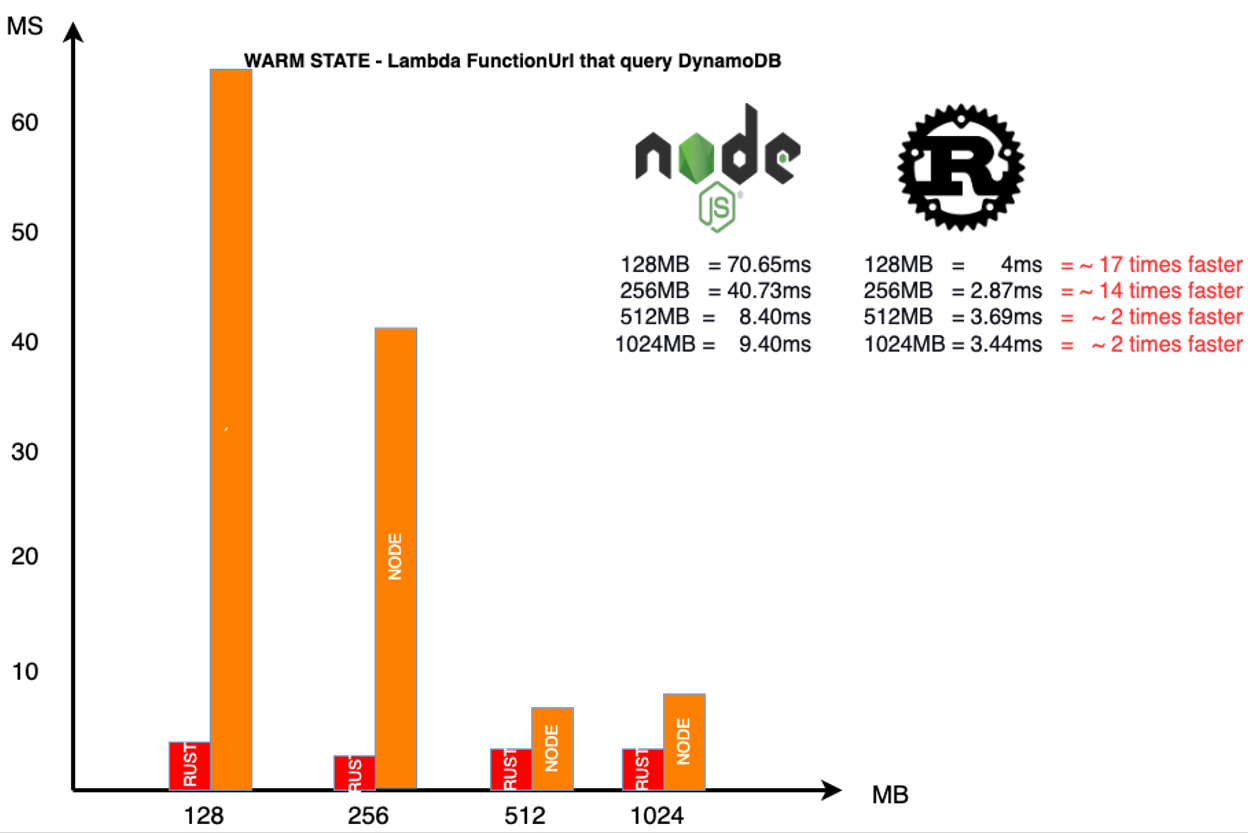
I can see the difference between one of the slowest and one of the fastest runtime. Put this on a scale like 1000 requests per second, continuously per month. You will save in computation between 15% and 35% (based on memory setting) without considering the increased throughput of the application and the overall benefits for your end-users.
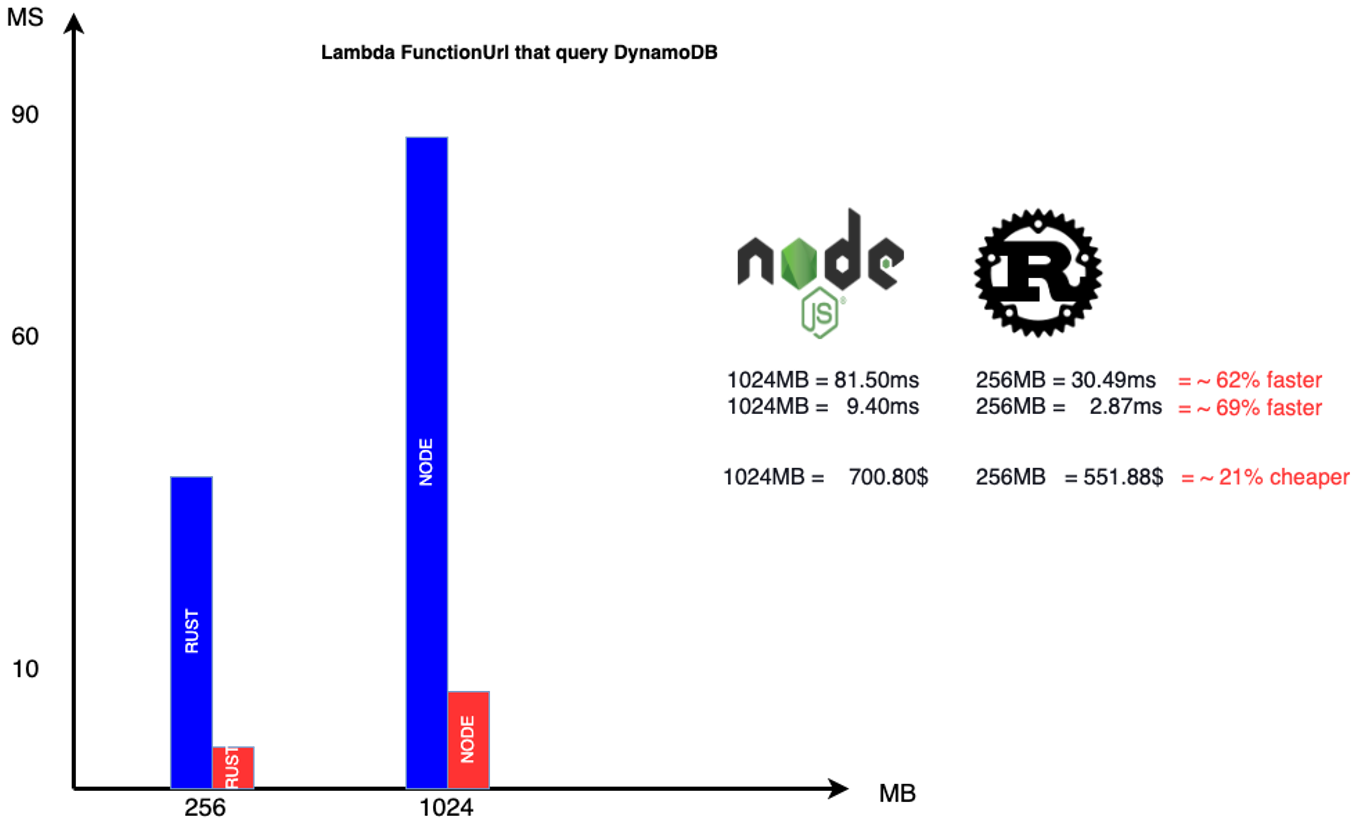
Do we need to rewrite all in Rust or Golang? Of course not. My goal here is that Serverless development is not like the old days. It allows more and gives you much more power and, if used correctly, will transform into a return never achieved before.

Imagine you are in Formula1, where milliseconds count. Which team do you want to be on? The winner one or the one that arrives last?