
Rust: Building An Async CSV Parser

In this post, I will be building a CSV parser. It will just be the server-side of the application.
Recently, I wrote how to parse a big CSV file in Rust here, and I have also made a comparison against other languages, especially with javascript here and running locally on my machine Rust resulted ten times faster.
Requirements
I want to upload from the IMDb Datasets the file title.basics.tsv.gz and save it into my data source.
Quotas
- Amazon API Gateway has a payload quota of 10 MB.
- AWS Lambda has a payload size of 6 MB.
The only solution is to upload the file into Amazon S3.
Architecture
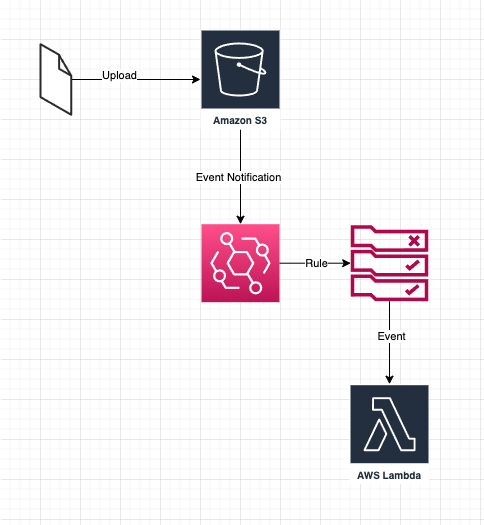
In this example, I assume the part for the pre-signed URL is already in place.
Once we upload the file into Amazon S3, the event notification to Amazon EventBridge is emitted and only if the rule match it will be sent to the AWS Lamda.
Finally, I will download the file and build a CSV parser.
The Amazon EventBridge rule is:
Events:
S3EventBridgeRule:
Type: EventBridgeRule
Properties:
InputPath: $.detail
Pattern:
source:
- aws.s3
detail:
bucket:
name:
- !ImportValue SourceBucket
object:
key:
- prefix: 'title.basics.tsv'
reason:
- PutObject
- CompleteMultipartUpload
As you can see, I have added PutObject and CompleteMultipartUpload as reasons, and it is because of the file size.
If you want to test it with files under 50 MB, the reason will be PutObject while over is CompleteMultipartUpload.
The input event is the following:
{
"account": "xxxxxx",
"detail": {
"bucket": {
"name": "MY_BUCKET_NAME"
},
"object": {
"etag": "6f090c9e813f9901b6b644e54542d",
"key": "title.basics.tsv",
"sequencer": "006203EA0EB9E87936",
"size": 262117
},
"reason": "PutObject",
"request-id": "BNXC24JOPWN721KF",
"requester": "xxxxxx",
"source-ip-address": "xxxxxx",
"version": "0"
},
"detail-type": "Object Created",
"id": "e425713c-bd60-ef37-f39b-66bbca4191b3",
"region": "eu-central-1",
"resources": ["arn:aws:s3:::MY_BUCKET_NAME"],
"source": "aws.s3",
"time": "2022-02-09T22:21:34Z",
"version": "0"
}
You can find all the code on my GitHub repository.
Serverless CSV Parser
Once I download the file and read each line, I can decide what to do. I did not do anything with the record, but I can insert it into DynamoDB or send the row into SQS.
Reading all the data from ByteStream into memory
pub async fn execute(aws_client: &AWSClient, event: S3Event, _ctx: Context) -> Result<(), Error> {
println!("{:?}", event);
let data = download_file(aws_client, &event).await?;
let buffer = &data[..];
let mut rdr = csv::ReaderBuilder::new()
.has_headers(true)
.delimiter(b'\t')
.double_quote(false)
.escape(Some(b'\\'))
.flexible(true)
.from_reader(buffer);
for result in rdr.deserialize() {
let record: Record = result?;
// do something with record
}
Ok(())
}
async fn download_file(aws_client: &AWSClient, event: &S3Event) -> Result<bytes::Bytes, Error> {
let result = aws_client
.s3_client
.as_ref()
.unwrap()
.get_object()
.bucket(event.bucket.name.to_string())
.key(event.object.key.to_string())
.send()
.await?;
let data = result.body.collect().await?.into_bytes();
Ok(data)
}
Because it is a memory parsing, the Lambda function must be provided with enough memory, and during my testing, I have noticed this error:
memory allocation of 440203771 bytes failed
Initially, the Lambda was set to 1024 MB. After this error, I moved to 3008MB even if the memory used was 1326 MB. I kept it realistic for extra manipulations inside the parser and possibly for the usage of other AWS Services.
I did some tests, and they are the results of all cold starts.
| CSV Size | Execution in ms |
| 256 KB | 93 |
| 15 MB | 433.09 |
| 440 MB | memory allocation error at 1024 MB |
| 700 MB | 17391.47 |
Reading data incrementally with StreamReader
pub async fn execute(aws_client: &AWSClient, event: S3Event, _ctx: Context) -> Result<(), Error> {
println!("{:?}", event);
let stream = aws_client
.s3_client
.as_ref()
.unwrap()
.get_object()
.bucket(event.bucket.name.to_string())
.key(event.object.key.to_string())
.send()
.await?
.body
.map(|result| result.map_err(|e| std::io::Error::new(std::io::ErrorKind::Other, e)));
// Convert the stream into an AsyncRead
let stream_reader = StreamReader::new(stream);
// Create a CSV reader
let mut csv_reader = csv_async::AsyncReaderBuilder::new()
.has_headers(true)
.delimiter(b'\t')
.double_quote(false)
.escape(Some(b'\\'))
.flexible(true)
.create_deserializer(stream_reader);
let mut count = 0;
// Iterate over the CSV rows
let mut records = csv_reader.deserialize::<Record>();
while let Some(record) = records.next().await {
let _record: Record = record?;
count += 1;
}
println!("COMPLETED {:?}", count);
Ok(())
}
The same file size 700M now has better performance into the Lambda function
| 700 MB | 3008 MB |
| All in memory | 17391.47 ms |
| StreamReader | 8913.24 ms |
Because the "Max Memory Used" decreased, I can now use a Lambda with less memory but higher execution. For example:
| Memory | 700 MB |
| 3008 MB | 8913.24 ms |
| 1024 MB | 13621.42 ms |
Special thanks to AWS SA Nicolas Moutschen for helping me with the StreamReader.
Conclusion
In the previous articles CSV processing, I mentioned using Amazon EFS or AWS Batch for processing big files, but this is only true if I need to persist them into a separated file for some reason. If this is not required, I can now use a simple Lambda function to process the entire file and decide what to do with each record. I could even save them in Amazon S3 and from there use Amazon Athena to extract the data into a CSV format.