
Rust for JavaScript developers: CSV comparison
speeeeeed

I am an AWS serverless community builder. I worked around Europe in public and private sector projects, and I have also been around for a while when Agile or Unit Tests were not a word.
I use this blog to share my ideas and create collaboration.
Feel free to contact me anytime.
I wrote about CSV processing and not just for processing a simple CSV of 3 rows but for a file of almost 1GB.
As a part of the mini-series Rust for JavaScript developers you can check out the other parts:
Part 1 I have shown a basic comparison for AWS SQS.
Part 2 I have shown a basic comparison for AWS AppConfig.
I intend to keep the mini-series focused on Lambda integration. Still, until the Lambda temporary storage is not increased in theory, this type of processing requires integration with Amazon EFS or AWS Batch.
Why
In the last few years, I have switched languages multiple times between .NET, JavaScript and Rust, and the knowledge acquired with one language is transferable to a new one. Therefore, we need mentally map the similarity to pick it quickly.
Because I was doing this with a friend who was curious to see Serverless Rust in action, I wrote small posts about it.
The Basic
Rust is coming with many built-in features, for example:
| JS | Rust |
| npm | cargo |
| npm init | cargo init |
| npm install | cargo install |
| npm run build | cargo build |
| package. json | Cargo.toml |
| package-lock. json | Cargo.lock |
| webpack | cargo build |
| lint | cargo clippy |
| prettier | cargo fmt |
| doc generation | cargo doc |
| test library like jest | cargo test |
Generate a new SAM based Serverless App
sam init --location gh:aws-samples/cookiecutter-aws-sam-rust
CSV Processing
Of course, each language has its library to use
| JS | Rust |
| imdb-dataset | csv |
| fast-csv |
Initially, I started with fast-csv, but it stopped the processing for a different escape reason. The input file is not so clean. I opted for the imdb-dataset library, not the fastest, but it does the job of processing all the rows.
The code side by side is pretty much the same.
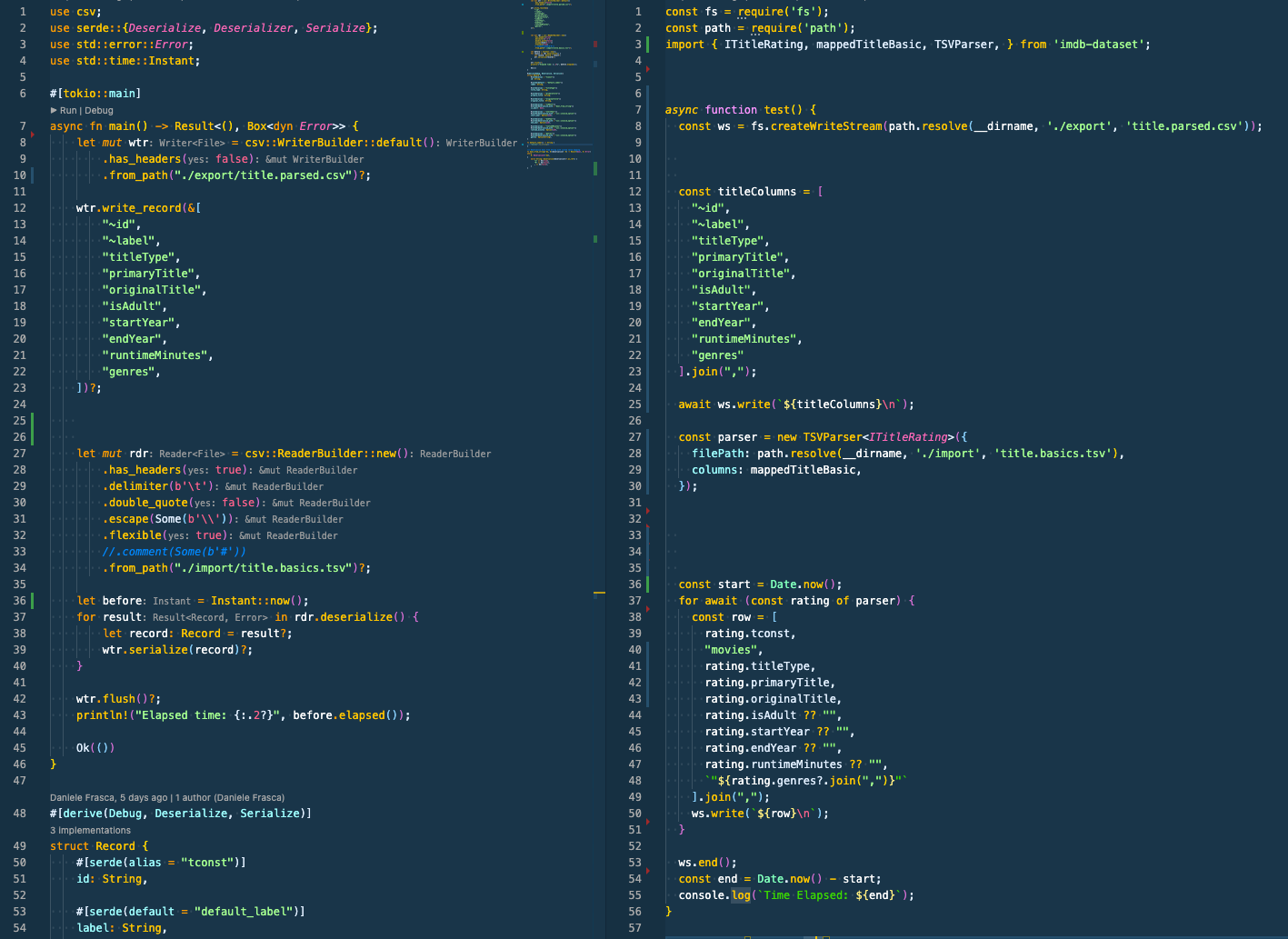
Please refer to CSV processing for the Rust explanation.
I kept the comparison simple, and whatever the language or library, it is all pretty much the same. A similar style would also be achieved using a fast-csv library.
const parse = csv.parse({
headers: true,
delimiter: "\t",
ignoreEmpty: true,
discardUnmappedColumns: true,
strictColumnHandling: true,
quote: "'",
escape: '"'
});
const transform = csv.format({ headers: true })
.transform((row) => (
{
"~id": row.tconst,
"~label": "person"
}
));
const start = Date.now();
fs.createReadStream(path.resolve(__dirname, './import', 'title.basics.tsv'))
.pipe(parse)
.on('error', (error) => console.error(error))
.on('data', (row) => { writeStream.write(row)})
.on('end', (rowCount) => {
writeStream.end();
const end = Date.now() - start;
console.log(`Elapsed time - millis: ${end}`);
});
Conclusion
The same processing can be done with both languages, but there is a significant difference, especially considering this CSV parsing could run into a Lambda. TIME.
I used the libraries as per their documentation, and perhaps with Javascript, the code can be improved, but it is a CSV, so it should work out of the box.
Here is the time to process around 8.6 million rows in the CSV with different languages:
| Language | Seconds |
| Rust | 5.1 |
| Js | 52 |
Bonus pack:
| Language | Seconds |
| Rust | 5.1 |
| Go | 6.6 |
| .NET | 15.9 |
| Js | 52 |
When we talk about serverless, speed is essential, and speed is money. Rust maybe is verbose perhaps does not have the perfect tooling around, but Rust is a great language, and it is an ideal match for Serverless computing.