




Building a multi-region application is hard, and there are a lot of questions to answer. Therefore, this blog post/series is not aiming to cover every single scenario.
The first question I should answer is:
Why bother with multi-region architectures?
My personal answer is to learn and explore possibilities that I am not exposed to in my typical day to day work life.
It is difficult to get exposure to such scenarios, and of course, each application is different from the other, so there is no standard way to do it.
I created a challenge building a hypothetical application to explore possible ways and throw questions that perhaps I will not answer.
Requirements
The application X got viral, so it must handle the following:
- The application is used in multiple European countries.
- The application is serverless.
- The application should have low latency.
- The application should be able to stand to a region failure.
- The application should scale.
And last but not least, the application should comply with data privacy laws like the GDPR.
Considerations
The requirements are very generic, so that I will make assumptions during my multi-region quest.
My regional application architecture is like this:
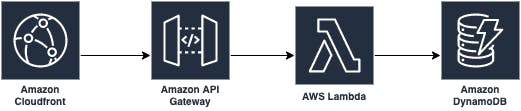
This blog series will focus on each component and answer each requirement.
Regions
Each region is a separate geographic area, and they are designed to be isolated from each other. Each region has multiple isolated locations called Availability Zones.
You can have a look at the AWS global infrastructure here.
I am interested in European countries, and so from the map, I can see that I have 6 regions and all of them have 3 availability zones. Serverless comes with built-in features like MultiAZ, Autoscaling easing, and leveraging each region's potential.
Scalability
Unfortunately, in the serverless world, the regions are not born equals. I have written here how it isn't easy to reach some scalability in some regions. This should be considered in this context, where the application will be under heavy traffic.
A way to help the scalability of the applications is to leverage, for example, the cache avoiding putting pressure on one of the chain's components. For instance, in our architecture:
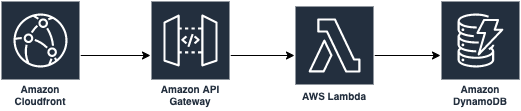
I can apply cache at each level, reducing the end-user latency and the pressure of each service and their quotas.
Availability/Reliability
I know that I can count on AWS services and infrastructure, so I need to make my service available.
It is worth remembering that even if my application is available does not mean that it is reliable. For example, I could contact the endpoint but still return 502 errors because I have reached the Lambda burst concurrency. However, making the application more reliable will, generally speaking, also make the application more available.
Some patterns and techniques can be used, and to mention some:
- queue
- stream
- retries
- circuit breaker
Depending on requirements and needs, combining them will help minimize failures.
Security
One of the requirements is the GDPR, but I am not an expert on this matter, and I can safely assume that some data cannot be visible and cannot be moved outside the residency region.
One thing that I can do is intercept data before the application process. So, for example, I could leverage the Lambda@Edge where I intercept data and encrypt all sensitive data. Then, when it reaches my services like APIGW, Lambda or DynamoDB, it is already encrypted.
I wrote a PoC a while ago, and the repository is available here.
About not leaving the region, I do not have an answer yet, but I guess not all the data stored is the same and so I could have maybe opportunities on this.
Conclusion
Multi-region architecture comport many challenges, and I cannot cover all. This series aims to analyze the primary options at my disposal, and in each post, I will try to evaluate what options AWS offers to handle this situation.
Stay tuned because, in the following posts, I will have a look at how to leverage:
To achieve my goal of Multi-region architecture on AWS.